
Archive for year: 2024
For every company in America, there are thousands of different variables that can positively or negatively affect its finances. Today we will focus on leveraging Decomposition Trees, Anomaly Detection, Key Influencers Charts to turn your data into strategic insights.
Labor costs, logistics, customer retention, partnerships and more all affect the day-to-day grind to keep a business afloat. And all of them come with their own unique problems to solve.
There are thousands of variables out there. And it’s important to understand how each engages with one another in order to optimize efficiency.
This is where AI and machine learning come in — particularly in the case of data visualization.
On a simple level, data visualization illustrates stats such as sales per month, KPI goals to hit, and revenue coming from different sections of a company.
And while this may show you what happened, it doesn’t paint the whole picture.
When you add AI and machine learning to these visualizations, you get a better idea of why exactly your figures are the way they are.
And that’s what I want to show you today.
There are dozens of tools out there that allow executives to make critical decisions including Tableau, Qlik, and Looker.
Today. I’m going to focus particularly on Microsoft Power BI and illustrate how you can apply AI and machine learning to its already existing visuals.
The AI Models
Time Series Models
Let’s say you’re looking at a sales chart from the year broken down by month. A normal line or bar chart will show you how much revenue came in monthly and will stop at the last month’s sales.
This is where AI changes everything.
Time series models allow you to predict future sales based on historical data and factors.
It uses a slew of different variables that would influence a metric like sales revenue and can give you an idea of where your future revenue will land in the coming months.
Data like seasonality, market trends and sales growth all affect revenue. And understanding these variables ahead of time can impact how to make crucial decisions.
This is within certainty, and the Time Series Model will consider that when predicting the future.
For instance, in a line graph, the area around your future line will be shaded to show where your revenue could end up.
Knowing this can help you avoid overspending or underutilizing the resources that you have at your disposal.
Regression Analysis
Next, let’s say that you want to answer the question of how much money is to be spent on marketing, and how this money spent affects sales.
Usually this can be easily seen on something like a scatterplot or bubble chart.
But with so many data points, it can be hard to see exactly where the optimal level would be.
With regression models, it would be able to give you further analysis into this, as it would analyze your data, and allow you to plot a proper regression trend line. This would give you an idea of exactly how much one variable, like marketing spending, affects another variable like sales revenue.
Furthermore, just like time series models, you can use regression models to predict future outcomes and have an idea of where you will end up depending on what actions you take.
The difference is that time series models depend on ordered data and time. Regression models instead focus on independent variables. This then allows you to see the result of variables that you haven’t tried yet, such as increasing marketing spending even more than you have in the past.
Clustering Analysis
Businesses often deal with a wide range of clients that can differ based on their behavior, demographics or purchase history.
Taking these different variables into consideration, you can use clustering to spot trends in graphs that may not be apparent at first glance.
On a scatterplot, for instance, clustering analysis would be able to circle and identify similar customers and show you how they trend, like the visual below:
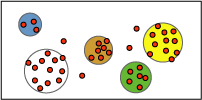
The different circled groups would represent whatever variable links the grouped individuals together such as age or buying frequency. In this way, you could target heavy buyers with more marketing or cater your product to a certain age demographic if you see that one is buying more than another.
Unique AI-Powered Visuals
Our AI tools are best used when they complement key metrics that need to be considered. With Power BI, you can use these visuals to better help paint a picture of why things are happening.
On top of adding this AI-driven data to normal charts, Power BI offers some unique AI-powered visuals that can help influence optimal decision making.
Key Influencers Chart
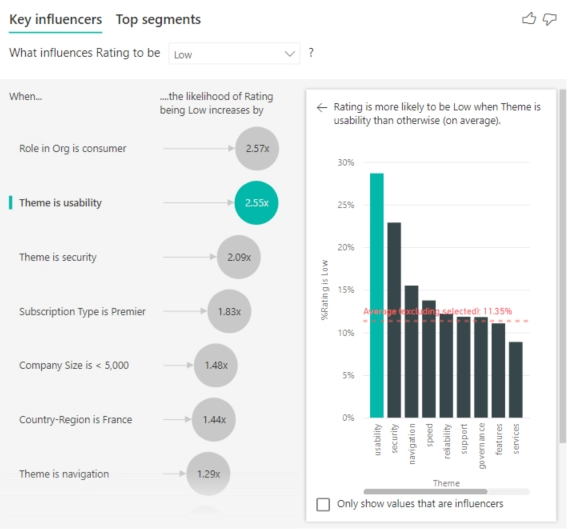
Let’s say, for instance, you are trying to understand what causes the most customer complaints.
Using a key influencers chart gives you insight into that question along with exactly how much each variable is responsible.
As you can see in the chart below, the number one influence is the type of customer, followed by a slew of different variables like theme type, company size and more:
What’s even better is that you can drill down into each topic. In doing so on the number one influencer, Role in Org is consumer, you can see that for this company, administrator is right behind consumer, and publisher is well below the other two:
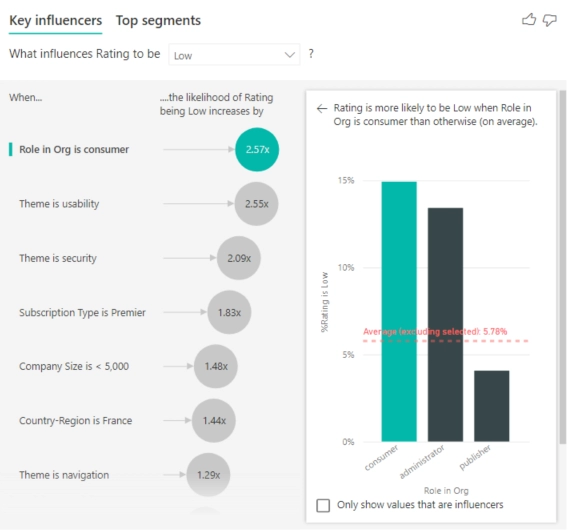
This kind of insight presented in a quick, easy-to-understand manner is huge when it comes to decision making and can give you a big advantage.
Of course, this is just one of the questions you can answer with a key influencers visual. Backorder likelihood, sales revenue, credit risk and more can be answered with the power of AI.
Decomposition Trees
Imagine that you are the head of a medical equipment company, and you are trying to tackle bringing down your percentage of backorders.
Decomposition trees exist so you can find the root of a problem by drilling down on a huge amount of data and categories.
Take the image below as an example:
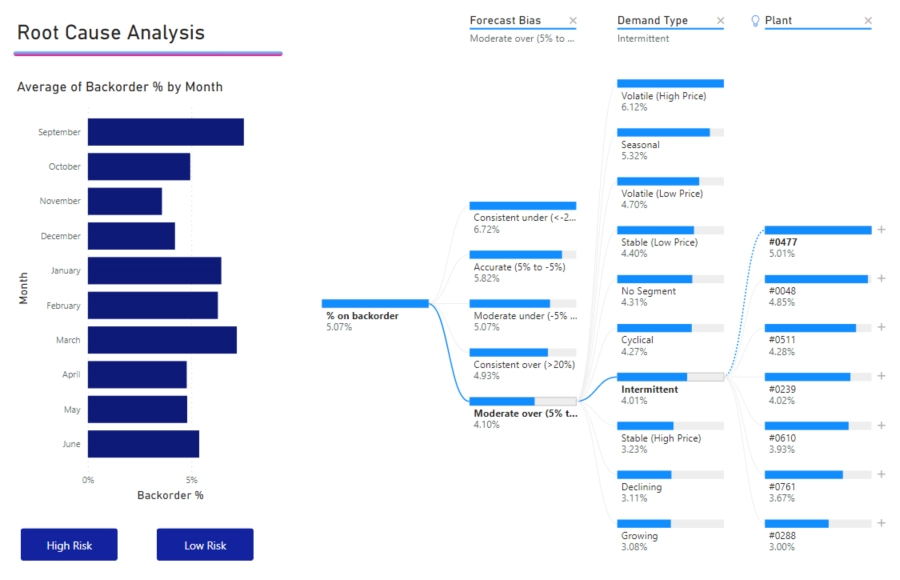
You can see from the image above that items who have intermittent demands are most likely on backorder from warehouse #0477.
On top of that, if you click a different route, the tree will recalculate your path and create a new set of data for you to look at.
As you can see in the image below, the cardiovascular products are much more delayed from Distribution Center A than B:
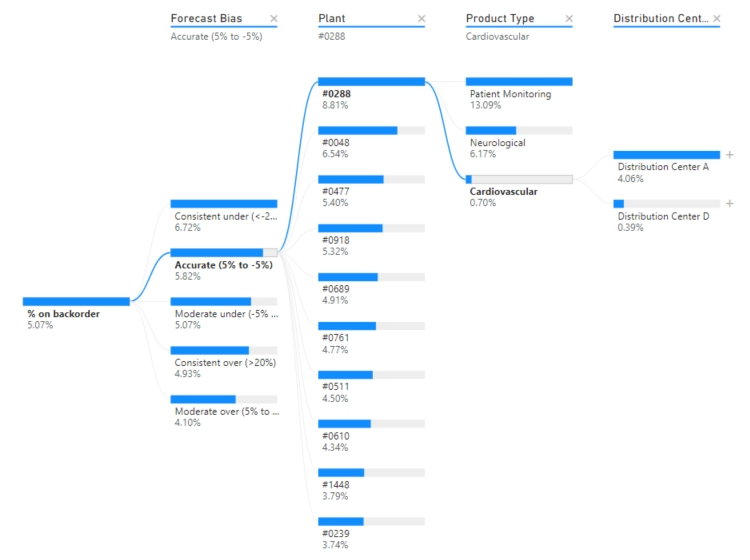 Knowing where exactly a problem lies allows you to make quick and efficient decisions. For instance, if you were partnered with one of these warehouses and found that it accounted for 80% of your backorders in one of your products, it would make sense to find a new partner that is more efficient in handling that product.
Knowing where exactly a problem lies allows you to make quick and efficient decisions. For instance, if you were partnered with one of these warehouses and found that it accounted for 80% of your backorders in one of your products, it would make sense to find a new partner that is more efficient in handling that product.
Anomaly Detection
When looking at sales from the year, there can sometimes be strange unexplained spikes in revenue. When this occurs, it is best to know exactly why this happened so proper action can be taken.
This is where AI comes in with its anomaly detection abilities.
Take a look at the image below:
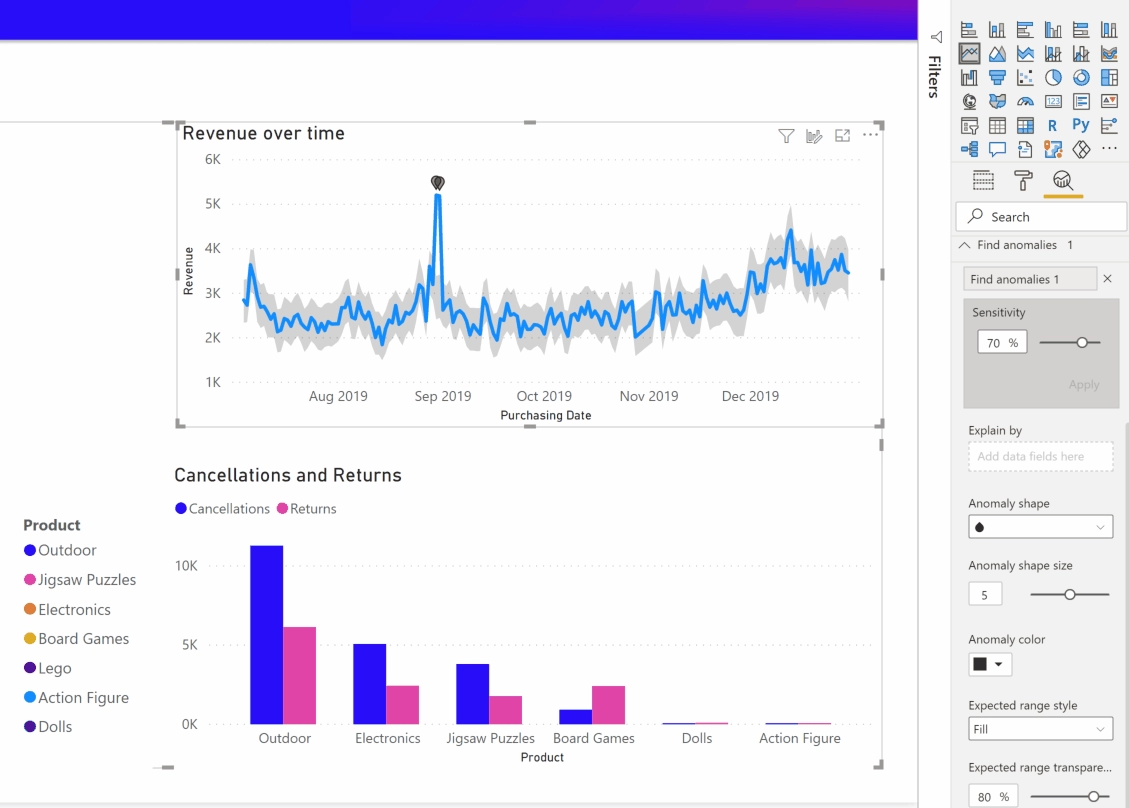
Anomaly Detection in Power BI helps you get actionable insights with your data!
That spike in September should be a red flag. And should trigger someone looking into why such a rise in revenue happened on that day.
Using Power Bi’s anomaly finder tool, you can add variables for it to take into account and have it give out a possible explanation for the strange day in sales.
In this case, the number one cause for this anomaly had to do with the ‘Region – West’ category. This could mean that either a client from the West region made a large purchase or that many individual customers did on that day.
Using this anomaly feature gives you a good starting point on finding out exactly why one day was very much unlike the others.
Tap Into AI’s Power Today
As we can see, the different Machine Learning and AI visualizations allow you gain an incredible amount of insight. And with this knowledge at your side, your ability to answer critical questions improves massively.
Its ability to identify problems, and identify unseen trends are unmatched. AI is turning industries upside down with its insight, and if you haven’t yet tapped into its potential yet, you’re missing out.
Contact us to start a discussion to see if ProcureSQL can guide you along Machine Learning and AI journey.

Securing data access is paramount for organizations of any size. Nobody wants to be the following data security leak that goes viral. Adopting robust authentication methods that enhance security, streamline user experience, and simplify management is crucial for decision-makers. Today, I write about how you could utilize Microsoft Entra ID to improve your database security footprint.
ProcureSQL recommends that Microsoft Entra ID replace traditional SQL authentication for Azure SQL Databases and Azure Managed Instances. Microsoft Entra ID offers benefits that address the shortcomings of SQL authentication.
What is SQL Server Authentication?
At the beginning of SQL Server, there was Windows Authentication and SQL Server Authentication. SQL Server Authentication is known as SQL Authentication. SQL Authentication allows users to connect with a username and password. SQL Authentication was helpful in environments where users were not part of a Windows domain or when applications needed to connect without using Windows credentials.
The Pitfalls of SQL Server Authentication
Here is why SQL authentication is inadequate:
Security Vulnerabilities
SQL authentication relies on username and password combination stored within the instance. This approach presents several security risks:
Password Attacks
SQL-authenticated accounts are susceptible to brute-force and dictionary attacks. If you have weak passwords, you rotate them infrequently; the bad guys can break through eventually.
Credential Storage
Passwords are often stored in connection strings or configuration files, increasing the risk of exposure.
Limited Password Policies
Most people don’t even implement SQL Server’s native password policy enforcement for SQL-authenticated accounts. Regardless, it is less robust than that of modern identity management systems.
Management Overhead
Decentralized Account Management
Every Azure Managed Instance or Azure SQL database requires separate account management. Managing all these accounts per instance or database increases the administrative burdens and the risk of inconsistencies.
Password Rotation Challenges
Implementing regular password changes across multiple databases and all their applications is complex and error-prone.
Wouldn’t it be nice if password rotation was in a single place?
The Microsoft Entra ID Authentication Advantage
Microsoft Entra authentication addresses these issues and significantly improves several key areas:
Enhanced Security
Centralized Identity Management
Microsoft Entra ID is a central repository for user identities, eliminating the need for separate database-level accounts per instance or database. This centralization reduces the attack surface and simplifies security management.
Robust Password Policies
Entra ID enforces strong password policies, including complexity requirements and regular password rotations. It also maintains a global banned password list, automatically blocking known weak passwords.
Multi-Factor Authentication (MFA) Support
The last thing we want to see is another data breach due to MFA not being enabled. Microsoft Entra authentication seamlessly integrates with Microsoft Entra MFA, adding an extra layer of security. Users can be required to provide additional verification, such as a phone call, text message, or mobile app notification.
Advanced Threat Protection
Microsoft Entra ID includes sophisticated threat detection capabilities that identify and mitigate suspicious login attempts and potential security breaches.
Improved Access Management
Role-Based Access Control (RBAC)
Entra ID allows for granular permission management through Azure RBAC, enabling administrators to assign specific database roles and permissions to users and groups.
Group Memberships
Administrators can create groups, automating access management as users join, move within, or leave the organization. Is it ideal to deactivate a user’s Entra ID account only and deactivate access everywhere when they leave?
Conditional Access Policies
Entra ID supports conditional access, allowing organizations to define conditions under which access is granted or denied. Examples can include users, device compliance, or network location.
Seamless Integration with Azure Services
Microsoft Entra authentication works harmoniously with other Azure services. Use managed identities for your service resources to simplify access management across the Azure ecosystem. Microsoft Entra Managed Identities eliminates the application needing a password similar to the Group Managed Service Accounts (gMSA) in Active Directory on-premise.
Streamlined User Experience
Single Sign-On (SSO)
Users can access Azure SQL databases using their organizational Microsoft Entra credentials, eliminating the need to remember multiple credentials.
Self-Service Password Reset
Entra ID offers self-service password reset capabilities to reduce the burden on IT helpdesks and the response to resolution time, improving user productivity.
Reduced Password Fatigue
Centralizing authentication simplifies password management for all users. Centralizing authentication results in better password management and reduced risk of using the same or similar passwords.
Compliance and Auditing
Comprehensive Audit Logs
By logging authentication events, Microsoft Entra ID offers improved visibility into user access patterns and potential security incidents.
Regulatory Compliance
Entra password authentication helps organizations meet regulatory requirements, such as GDPR, HIPAA, and PCI DSS, by providing strong authentication and detailed audit trails.
Integration with Azure Policy
Organizations can enforce compliance at scale by defining and implementing Azure Policies that govern authentication methods and access controls.
Implementation Considerations
While the benefits of Microsoft Entra Authentication are clear, decision-makers should consider the following when planning a migration:
Hybrid Environments
For organizations with on-premises Active Directory, Microsoft Entra Connect can synchronize identities, enabling a smooth transition
Application Compatibility
Ensure all applications connecting to Azure SQL databases support Microsoft Entra Authentication methods.
Training and Change Management
Plan for user education and support to ensure a smooth transition from SQL Authentication to Entra password authentication.
Gradual Migration
Consider a phased approach, migrating critical databases first and gradually expanding to the entire environment.
Final Thoughts
As information technology leaders, moving from SQL Authentication to Microsoft Entra Authentication for Azure SQL databases and Managed Instances is strategic. This transition addresses the security vulnerabilities and management challenges of SQL Authentication and paves the way for a more secure, compliant, and user-friendly database access experience. Adopting Microsoft Entra Authentication for Azure SQL databases is not just a best practice—it’s necessary for forward-thinking IT leaders committed to safeguarding their organization’s digital future in Azure.
About ProcureSQL
ProcureSQL is the industry leader in providing data architecture as a service to enable companies to harness their data to grow their business. ProcureSQL is 100% onshore in the United States and supports the four quadrants of data, including application modernization, database management, data analytics, and data visualization. ProcureSQL works as a guide, mentor, leader, and implementor to provide innovative solutions to drive better business outcomes for all businesses. Click here to learn more about our service offerings.
Every year, hundreds of billions of packages are shipped around the world. And in 2023 alone, that number broke the record at 356 billion shipped worldwide.
That’s a 100% increase since 2016. The industry will only get bigger and more complex, as estimates show that by 2028, nearly 500 billion packages will be shipped globally.
As supply chains become more bloated with delivery demand, they become more complex, multiplying efficiency problems.
This is where Machine Learning and Artificial Intelligence (AI) step in.

If you are not using Machine Learning, you are falling behind.
Companies worldwide, including many Fortune 500 names, have turned to Machine Learning and Artificial Intelligence to fine-tune their logistics and, most importantly, increase revenue and reduce costs.
When shipping out millions of packages per year, saving 5% in cost at every step is a massive boost to profits.
The numbers don’t lie either. Companies have already shown that AI is helping them meet their revenue goals. According to McKinsey, 61% of manufacturing executives report decreased costs, and 53% report increased revenues as a direct result of introducing AI into their supply chain.
Three Common Machine Learning Models
Several kinds of Machine Learning models have been designed to tackle different problems. Today, I will focus on three types of modeling systems: Time Series Models, Regression Models, and Classification Models.
Each offers something unique, and all can lead to efficiency improvements in the supply chain in different ways…
Â
Time Series Forecasting Models
Â
Time series forecasting is as simple as it gets when you want to improve efficiency with Machine Learning. The model takes historical data such as sales, seasonality, and trends and uses it to make predictions for the future.
Â
For instance, let’s say you’re in the clothing apparel business and need to stock your warehouses full of winter gear for the upcoming season. Time Series forecasting would allow you to look at previous years’ sales and show you exactly when to stock winter gear for the upcoming cold months. This means you won’t stock too much wrong gear too early and take up precious space.
Â
Likewise, it can keep you prepared for any major spikes in a single item based on sales trends. If you notice that in November, sales of winter apparel increase by 40%, you can ensure you aren’t caught off guard and avoid the risk of being understocked.
Â
In doing so, you also keep customers happy, knowing they can always get the item they need. Plus, you’re meeting the demand of what they will buy. Very few are buying sandals in January. But if you find out that data shows that it’s still 10% of your sales, you might as well keep selling them and not lose out on that profit.
Â
Regression Models
Â
A regression model is an AI tool that finds the relationships between two variables and how one affects the other.
Â
In our supply chains, regression models are well-equipped to aid in predicting delivery times of goods. The reason is that there are so many variables that go into transportation such as distance, weather conditions, and traffic.
Â
Machine Learning and AI can look at the historical data of all of these variables and give you a leg up on the proper route to send your material from point A to point B. If you can avoid traffic, reroute around bad weather, and fully optimize routes taken, then you save on gas and time — reducing overall costs in the process.
Â
Much like time series forecasting, regression models also allow you to predict demand on how big of a staff you need. If you’re in charge of a warehouse, for instance, variables such as the number of orders, seasonality, and even the day of the week affect exactly how many staff you need to pick items, box up, and ship out orders.
Â
Furthermore, these factors affect how large of a fleet you need to be able to deliver your items. Having two trucks does no good when your demand requires eight. Likewise, having 100 workers at a warehouse doesn’t make sense when you only need 20 working that day.
Â
Classification Models
Â
Finally, let’s talk about classification models — AI tools designed to factor in many different variables and allow you to assess a wide variety of things from risk assessment to how to market to certain customers.
Â
For instance, when it comes to risk assessment, you could use a classification model to let you know which items are particularly prone to getting damaged. Factors that you could put in are the packaging used to handle the item, travel conditions (if it is going to be on a bumpy road or in extreme temperatures), and distance (how many different handlers are going to touch it).
Â
If you know all of these factors ahead of time, and allow AI to assess it as a high or low-risk item, then you can take precautions so it doesn’t arrive damaged. You can beef up the packaging, adhere to strict orders, or arrange for special transportation to ensure that nothing goes wrong.
Â
On top of that, when delivering items, you can use classification models to determine if a package is at a high or low risk of arriving late. Factoring in traffic, weather, distance, holiday seasonality, and package weight all are factors that you can use to give an estimate of when something can be delivered. This keeps customers and clients happier, as they’ll have a better understanding of when exactly they will receive their items.
Â
Finally, you can even group your customers into different categories to give you a better idea of who to target with internal marketing. For instance, those with high spending habits or those that always pick next-day delivery would be more worth your while to target with marketing efforts than those that spend less or select standard delivery.
Â
Machine Learning Can Improve Your Business Today
Â
As we can see, the different Machine Learning and AI models out there offer a huge variety of insight across the board when it comes to supply chains.
The best part is that the examples I mentioned are only the tip of the iceberg when it comes to providing solutions to supply chains and logistics.
Machine Learning and AI have changed the game from inventory management to quality control to delivery efficiency and more. Its ability to fine-tune processes and optimize efficiency gives companies a leg up on their competitors. And every year, AI and Machine learning models get better and better.
With companies from Walmart to Nike to FedEx and more adopting Machine Learning and AI into their supply chains, it only makes sense that other companies mimic their success and do the same.
Contact us to start a discussion about whether ProcureSQL can guide you along your Machine Learning and AI journey.
In this post, we will cover a new feature in preview for Microsoft Fabric: Lakehouse Schemas. If your Lakehouse is drowning in a sea of unorganized data, this might just be the lifeline you’ve been looking for.
The Data Chaos Conundrum
We’ve all been there. You’re knee-deep in a project, desperately searching for that one crucial dataset. It’s like trying to find your car keys in a messy apartment; frustrating and time-consuming. This is where Lakehouse Schemas come in, ready to declutter your data environment and give everything a proper home.
Lakehouse Schemas: Your Data’s New Best Friend
Think of Lakehouse Schemas as the Marie Kondo of the data world. They help you group your data in a way that just makes sense. It’s like having a super-organized filing cabinet for your data.
Why You’ll Love It
- Logical Grouping: Arrange your data by department, project, or whatever makes the most sense for you and your team.
- Clarity: No more data haystack. Everything has its place.
The Magic of Organized Data
Let’s break down how these schemas can transform your data game:
Navigate Like a Pro
Gone are the days of endless scrolling through tables. Prior to this feature, if your bronze layer had a lot of sources and thousands of tables, being able to find the exact table in your Lakehouse was a difficult task. With schemas, finding data just became a lot easier.
Pro Tip: In bronze, organize sources into schemas. In silver, organize customer data, sales data, and inventory data into separate schemas. Your team will thank you when they can zoom right to what they need.
Schema Shortcuts: Instant Access to Your Data Lake
Here’s where it gets even better. Schema Shortcuts allow you to create a direct link to a folder in your data lake. Say you have a folder structure on your data lake like silver/sales filled with hundreds of Delta tables, creating a schema shortcut to silver/sales automatically generates a sales schema. It then discovers and displays all the tables within that folder structure instantly.
Why It Matters: No need to manually register each table. The schema shortcut does the heavy lifting, bringing all your data into the Lakehouse schema with minimal effort.
Note: Table names with special characters may route to the Unidentified folder within your lakehouse, but they will still show up as expected in your SQL Analytics Endpoint.
Quick Tip: Use schema shortcuts to mirror your data lake’s organization in your Lakehouse. This keeps everything consistent and easy to navigate.
Manage Data Like a Boss
Ever tried to update security on multiple tables at once? With schemas, it’s a walk in the park.
Imagine This: Need to tweak security settings? Do it once at the schema level, and you’re done. No more table-by-table marathon.
Teamwork Makes the Dream Work
When everyone knows where everything is, collaboration becomes a whole lot smoother.
Real Talk: Clear organization means fewer “Where’s that data?” messages and more actual work getting done.
Data Lifecycle Management Made Easy
Keep your data fresh and relevant without the headache.
Smart Move: Create an Archive or Historical schema for old data and a “Current” schema for the hot stuff. It’s like spring cleaning for your data!
Take Control with Your Own Delta Tables
Managing your own Delta tables is added overhead, but gives you greater flexibility and control over your data, compared to relying on fully managed tables within Fabric.
The Benefits:
- Customization: Tailor your tables to fit your specific needs without the constraints of Fabric managed tables.
- Performance Optimization: Optimize storage and query performance by configuring settings that suit your data patterns. Be aware that you must maintain your own maintenance schedules for optimizations such as vacuum and v-order when managing your own tables.
- Data Governance: Maintain full control over data versioning and access permissions.
Pro Tip: Use Delta tables in conjunction with schemas and schema shortcuts to create a robust and efficient data environment that you control from end to end.
Getting Started: Your Step-by-Step Guide
Ready to bring order to the chaos? Here’s how to get rolling with Lakehouse Schemas:
Create Your New Lakehouse
At the time of writing this, you can not enable custom schemas on existing Lakehouses. You must create a new Lakehouse and check the Lakehouse schemas checkbox. Having to redo your Lakehouse can be a bit of an undertaking if all of your delta tables are not well-organized, but getting your data tidied up will pay dividends in the long run.
Plan Your Attack
Sketch out how you want to organize things. By department? Project? Data type? You decide what works best for you and your team.
Create Your Schemas
Log into Microsoft Fabric, head to your Lakehouse, and start creating schemas. For folders in your data lake, create schema shortcuts to automatically populate schemas with your existing tables.
Example: Create a schema shortcut to silver/sales, and watch as your Lakehouse schema fills up with all your sales tables, no manual import needed.
Play Data Tetris
If you choose not to use schema shortcuts. you can move any tables into their new homes. It’s as easy as drag and drop. If you are using schema shortcuts, any shifting of schemas would occurs in the data lake location of your delta table in your data pipelines.
Manage Your Own Delta Tables
Consider creating and managing your own Delta tables for enhanced control. Store them in your data lake and link them via schema shortcuts.
Stay Flexible
As your needs change, don’t be afraid to shake things up. Add new schemas or schema shortcuts, rename old ones, or merge as needed.
Pro Tips for Schema Success
- Name Game: Keep your schema names clear and consistent. Work with the business around naming as well to help prevent any confusion around what is what.
- Leverage Schema Shortcuts: Link directly to your data lake folders to auto-populate schemas.
- Document It: Document what goes where. Future you will be grateful, and so will your team.
- Team Effort: Get everyone’s input on the structure. It’s their data home too.
- Own Your Data: Manage your own Delta tables for maximum flexibility.
- Stay Fresh: Regularly review and update your schemas setup and configuration.
The Big Picture
Organizing your data isn’t just about tidiness—it’s about setting yourself up for success.
- Room to Grow: A well-planned schema system scales with your data.
- Time is Money: Less time searching means more time for actual analysis.
- Take Control: Managing your own Delta tables adds some overhead but also gives you the flexibility to optimize your data environment and more control.
- Instant Access: Schema shortcuts bridge your data lake and Lakehouse seamlessly.
- Roll with the Punches: Easily adapt to new business needs without a data meltdown.
Wrapping It Up
Microsoft Fabric’s Lakehouse Schemas and Schema Shortcuts are like a superhero cape for your Lakehouse environment. They bring order to chaos, boost team productivity, and make data management a breeze.
Remember:
- Schemas create a clear roadmap for your data.
- Schema shortcuts automatically populate schemas from your data lake folders.
- Managing your own Delta tables gives you more control and efficiency.
- Your team will work smarter, not harder.
- Managing and updating data becomes way less of a headache.
So why not give the new Lakehouse Schemas feature a shot? Turn your data jungle into a well-organized garden and watch your productivity grow!
Happy data organizing!
Are you tired of people complaining about your database’s slow performance? Maybe you are tired of looking at the black box and hoping to find what is slowing your applications down. Hopefully, you are not just turning your server off and back on when people say performance is terrible. Regardless, I want to share a quick SQL Server performance-tuning checklist that Informational Technology Professionals can follow to speed up their SQL Server instances before procuring a performance-tuning consultant.
Bad SQL Server performance usually results from bad queries, blocking, slow disks, or a lack of memory. Benchmarking your workload is the quickest way to determine if performance worsens before end users notice it. Today, we will cover some basics of why good queries can go wrong, the easiest way to resolve blocking, and how to detect if slow disks or memory is your problem.
The Power of Up-to-Date Statistics: Boosting SQL Server Performance
If you come across some outdated SQL Server performance tuning recommendations, they might focus on Reorganizing and Rebuilding Indexes. Disk technology has evolved a lot. We no longer use spinning disks that greatly benefit from sequential rather than random reads. On the other hand, ensuring you have good, updated statistics is the most critical maintenance task you can do regularly to improve performance.
SQL Server uses statistics to estimate how many rows are included or filtered from the results you get when you add filters to your queries. Suppose your statistics are outdated or have a minimal sample rate percentage, which is typical for large tables. In both cases, your risk is high for inadequate or misleading statistics, making your queries slow. One proactive measure to prevent performance issues is to have a maintenance plan to update your statistics on a regular schedule. Updating your stats with a regularly scheduled maintenance plan is a great start.
For your very large tables, you will want to include a sample rate. This guarantees an optimal percentage of rows is sampled when update statistics occur. The default sample rate percentage goes down as your table row count grows. I recommend starting with twenty percent for large tables while you benchmark and adjust as needed—more on benchmarking later in this post.
Memory Matters: Optimizing SQL Server Buffer Pool Usage
All relational database engines thrive on caching data in memory. Most business applications do more reading activity than writing activity. One of the easiest things you can do in an on-premise environment is add memory and adjust the max memory setting of your instance, allowing more execution plans and data pages to be cached in memory for reuse.
If you are in the cloud, it might be a good time to double-check and ensure you use the best compute family for your databases. SQL Server’s licensing model is per core; all cloud providers pass the buck to their customers. You could benefit from a memory-optimized SKU with fewer CPU cores and more RAM. Instead of paying extra for CPU cores, you don’t need so you can procure the required RAM.
Ideally, we would be using the enterprise edition of SQL Server. You would also have more RAM than the expected size of your databases. If you use the Standard edition, ensure you have more than 128GB of RAM (the maximum usage) for SQL Server Standard Edition. If you use the Enterprise edition of SQL Server, load your server with as much RAM as possible, as there is no limit to how much RAM can be utilized for caching your data.
While you might think this is expensive, it’s cheaper than paying a consultant to tell you you would benefit from having more RAM and then going and buying more RAM or sizing up your cloud computing.
Disks Optimization for SQL Server Performance
The less memory you have, the more stress your disks experience. This is why we prioritize focusing on memory before we concentrate on disk. With relational databases, we want to follow three metrics for disk activity. We will focus on the number of disk transfers (reads and writes) that occur per second, also known as IOPS. Throughput is also known as the total size of i/o per second. Finally, we focus on latency, the average time it takes to complete the i/o operations.
Ideally, you want your reads and writes to be as fast as possible. More disk transfers lead to increased latency. If your reads or writes latency is consistently above 50ms, your I/O is slowing you down. You must benchmark your disk activity to know when you reach your storage limits. You either need to improve your storage or reduce the I/O consumption.
Read Committed Snapshot Isolation: The Easy Button to Reduce Blocking Issues
Does your database suffer from excessive blocking? By default, SQL Server uses pessimistic locking, which means readers and writers will block writers. Read Committed Snapshot Isolation (RCSI) is optimistic locking, which reduces the chance that a read operation will block other transactions. Queries that change data block other queries trying to change the same data.
Utilizing RCSI is an way to improve your SQL Server performance when you queries are slow due to blocking. RCSI works by leveraging tempdb to store row versioning. Any transaction that changes data stores the old row version in an area of tempdb called the version store. If you have disk issues with tempdb, this could add more stress. which is why we want to focus on disk optimizations before implementing RCSI.
You Are Not Alone: Ask For Help!

You are not alone. Procure SQL can help you with your SQL Server Performance Tuning questions.
If you have reached this step after following the recommendations for statistics, memory, disks, RCSI? If so, this is a great time to contact us or any other performance-tuning consultant. A qualified SQL Server performance tuning consultant could review your benchmarks with you and identify top offenders that could then be tuned with the possibility of indexes, code changes, and other various techniques.
If you need help, or just want to join our newsletter fill out the form below, and we will gladly walk with you on your journey to better SQL Server performance!
Why Adopting a Modern Data Warehouse Makes Business Sense
Most traditional data warehouses are ready for retirement. When they were built a decade or more ago, they were helpful as a mechanism to consolidate data, analyze it, and make business decisions. However, technology moves on, as do businesses, and in modern times, many data warehouses are showing their age. Most of them rely on on-premises technology that can be limited to scalability, and they also may contain old or incorrect rules and data sets, which can cause organizations to make misguided business assumptions and decisions. Traditional data warehouses can also impede productivity by being very slow when compared to current solutions – processes that may take hours with an old data warehouse take a matter of minutes with a modern one.
These are among the reasons why many organizations seek to migrate to a modern data warehouse solution – one that is faster, more scalable, and easier to maintain and operate than traditional data warehouses. Moving to a modern data warehouse might seem like a daunting process, but this migration can be dramatically eased with the help of a data-managed service provider (MSP) that can provide the recommendations and services required for a successful migration.
This blog post will examine the advantages of moving to a modern warehouse.
Addressing the speed problem
With older on-premises data warehouses, processing speed can be a major issue. For example, if overnight extraction, transformation, and loading (ETL) jobs go wrong, it can lead to a days-long project to correct.
Processing is much faster with a modern data warehouse. Fundamentally, modern systems are built for large compute and parallel processing rather than relying on slower, sequential processing. Parallel processing means you can do more things independently rather than doing everything in one sequence, which can be an enormous waste of time. This ability to do other things while conducting the original processing job has a significant positive impact on scalability and worker productivity.
As part of the transition to a modern data warehouse, users can move partially or entirely to the cloud. Â One of the most compelling rationales, as with other cloud-based systems, is that cloud-based data warehouses are an operational cost rather than a capital expense. The reason for this is capital expenses involved with procuring hardware, licenses, etc. are outsourced to a third-party cloud services provider.
The other benefits of moving to the cloud are well understood but having effective in-house data expertise is needed for any environment – on-premises, cloud, or hybrid. This enables organizations to take full advantage of moving to a modern data warehouse. Among the benefits:
- While it is true that functions like backups, updates, and scaling are just features in the cloud that can be clicked to activate, customers also must provide in-house data expertise to determine important things like recovery time objective (RTO) and recovery point objective (RPO). This cloud/on-premises collaboration is key to successfully recovering data, which is the rationale for doing backups in the first place.
- Parallel processing makes the data warehouse much more available. Older data warehouses use sequential processing, which is much slower for data ingestion and integration. Regardless of the environment, data warehouses need to exploit parallel processing to avoid the speed problems inherent in older sequential systems.
- Real-time analytics become more available with a cloud-based data warehouse solution. Just as with other technologies like artificial intelligence, using the latest technology is much easier when a provider has it available for customers.
The important thing to remember is that moving to a modern data warehouse can be done at any speed—it doesn’t have to be a big migration project. Many organizations wait for their on-premises hardware contracts and software licenses to expire before embarking on a partial or total move to the cloud.
Addressing the reporting problem
As part of the speed problem, reports often take a long time to generate from old data warehouses. When moving to a modern data warehouse, the reporting is changed to a semantic and memory model, which makes it much faster. For end-users, they can move from a traditional reporting model to interactive dashboards that are near real-time. This puts more timely and relevant information at their fingertips that they can use to make business decisions.
Things also get complicated when users run reports against things that are not a data warehouse. The most common situations are they’ll run a report against an operational data store, they’ll report against a copy of straight data from production enterprise applications, or they’ll download data to Excel and manipulate it to make it useful. All of these approaches are fragmented and do not give the complete and accurate reporting that comes from a centralized data warehouse.
The move to a modern data warehouse eliminates these issues by consolidating reporting around a single facility, reducing the effort and hours consumed by reporting while adopting a new reporting structure that puts more interactive information in decision-makers hands.

Addressing the data problem
As we said before, most OLAP data warehouses are a decade or more old. In some cases, they have calculations and logic that aren’t correct or were made on bad assumptions at the time of design. This means organizations are reporting on potentially bad data and, worse yet, making poor business decisions based on that data.
Upgrading to a modern data warehouse involves looking at all the data, calculations, and logic to make sure they are correct and aligned with current business objectives. This improves data quality and ends the “poor decisions on bad data†problem.
This is not to say that data warehouse practitioners are dropping the ball. It may be that the data was originally correct, but over time logic and calculations become outmoded due primarily to changes in the organization. Moving to a modern data warehouse involves adopting current design patterns and models and weeding out the data, calculations, and logic that are not correct.
This upgrade can be done with the assistance of a data MSP that can provide the counsel and services involved with reviewing and revising data and rules for a new data warehouse, provide the pros and cons of deployment models, and recommend the features and add-ons required to generate maximum value from a modernization initiative.
The big choice
CIOs and other decision-makers have a choice when it’s time to renew their on-premises data warehouse hardware contracts: “Do I bite the bullet and do the big capital spend to maintain older technology, or do I start looking at a modern option?â€
A modern data warehouse provides a variety of benefits:
- Much better performance through parallel processing.
- Much faster and more interactive reporting.
- Lower maintenance cost.
- Quicker time to reprocess and recover from error.
- An “automatic†review of business rules and logic to ensure correct data is being used to make business decisions.
- Better information at end-users’ fingertips.
Moving to a modern data warehouse can be a gradual move to the cloud, or it can be a full migration. The key is to get the assistance of ProcureSQL who specializes in these types of projects to ensure that things go as smoothly and cost-effectively as possible.
Contact us to start a discussion to see if ProcureSQL can guide you along your data warehouse journey.
This year, several data breaches were caused by multi-factor authentication NOT being enabled.

If you ever follow any of our tips, blogs, or videos, please follow this one and enable multi-factor authentication on all your applications and websites that you access.
If you are procuring a new application or service, now is also a great time to verify that it includes forcing multi-factor authentication.
Hello, Everyone; this is John Sterrett from Procure SQL. Today, we will discuss how you can validate SQL Server Backups with a single line of PowerShell.
Due to the recent global IT outage, I thought this would be an excellent time to focus on the last line of defense—your database backups. I have good news if you are not validating your SQL Server backups today.
DbaTools Is Your Friend
Did you know you can validate your backups with a single PowerShell line? This is just one of several amazing things you can do with dbatools in a single line of PowerShell.
John, what do you mean by validating SQL Server backups?
- I mean, find your last backup
- See if the backup still exist
- Restore the previous backup(s)
- Run an Integrity Check
- Document the time it took along the way
Validating SQL Server Backups – How Do We Validate Our Backups?
DBATools has a module named Test-DbaLastBackup.
You could run it with the following command to run against all your databases using the instance name provided below.
$result = Test-DbaLastBackup -SqlInstance serverNameGoesHereYou could also have it run for a single database with a command similar to the one below.
$result = Test-DbaLastBackup -SqlInstance serverNameGoesHere -Database ProcureSQLWhat happens with Test-DbaLastBackup?
Great question! If we learned anything from the recent global IT downtime, it’s to validate and test everything!
I love to see what’s happening under the hood, so I set up an extended event trace to capture all the SQL statements running. I can see the commands used to find the backups, the restore, the integrity check, and the dropping of the database created during the restore.
All the excellent things I will share are below.
Extended Event
The following is the script for the extended event. I run this to capture events created by my DBATools command in Powershell. Once I start the extended event trace, I run the PowerShell command to do a single check on a database, as shown above. I then stop the capture and review.
CREATE EVENT SESSION [completed] ON SERVER
ADD EVENT sqlserver.sp_statement_completed(
ACTION(sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.database_name,sqlserver.query_hash,sqlserver.session_id,sqlserver.sql_text,sqlserver.username)
WHERE ([sqlserver].[like_i_sql_unicode_string]([sqlserver].[client_app_name],N'dbatools PowerShell module%'))),
ADD EVENT sqlserver.sql_batch_completed(
ACTION(sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.database_name,sqlserver.query_hash,sqlserver.session_id,sqlserver.sql_text,sqlserver.username)
WHERE ([sqlserver].[like_i_sql_unicode_string]([sqlserver].[client_app_name],N'dbatools PowerShell module%'))),
ADD EVENT sqlserver.sql_statement_completed(
ACTION(sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.database_name,sqlserver.query_hash,sqlserver.session_id,sqlserver.sql_text,sqlserver.username)
WHERE ([sqlserver].[like_i_sql_unicode_string]([sqlserver].[client_app_name],N'dbatools PowerShell module%')))
ADD TARGET package0.event_file(SET filename=N'completed',max_file_size=(50),max_rollover_files=(8))
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF)
GOValidate SQL Server Backups – Resulting Events / Statements
Here, you can see we captured many SQL Statements during this capture. Below, I will minimize and focus on key ones that prove what happens when you run this command for your database(s).
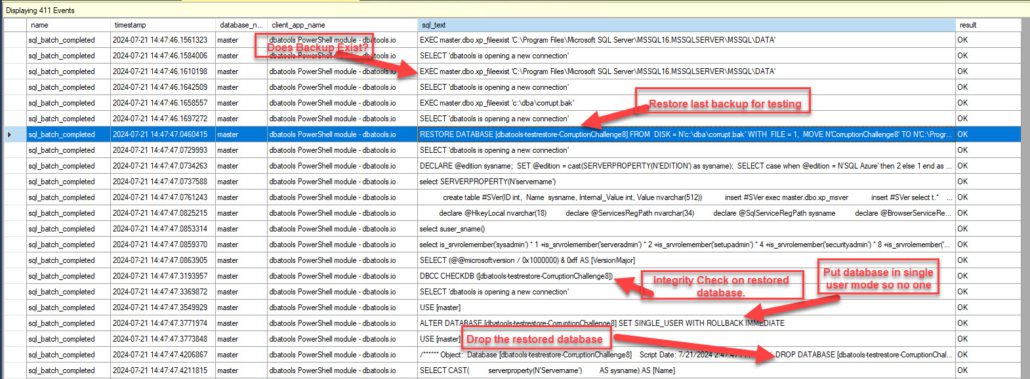
The query used to build up the backup set to find the last backup was too big to screenshot, so I included it below.
/* Get backup history */
SELECT
a.BackupSetRank,
a.Server,
'' as AvailabilityGroupName,
a.[Database],
a.DatabaseId,
a.Username,
a.Start,
a.[End],
a.Duration,
a.[Path],
a.Type,
a.TotalSize,
a.CompressedBackupSize,
a.MediaSetId,
a.BackupSetID,
a.Software,
a.position,
a.first_lsn,
a.database_backup_lsn,
a.checkpoint_lsn,
a.last_lsn,
a.first_lsn as 'FirstLSN',
a.database_backup_lsn as 'DatabaseBackupLsn',
a.checkpoint_lsn as 'CheckpointLsn',
a.last_lsn as 'LastLsn',
a.software_major_version,
a.DeviceType,
a.is_copy_only,
a.last_recovery_fork_guid,
a.recovery_model,
a.EncryptorThumbprint,
a.EncryptorType,
a.KeyAlgorithm
FROM (
SELECT
RANK() OVER (ORDER BY backupset.last_lsn desc, backupset.backup_finish_date DESC) AS 'BackupSetRank',
backupset.database_name AS [Database],
(SELECT database_id FROM sys.databases WHERE name = backupset.database_name) AS DatabaseId,
backupset.user_name AS Username,
backupset.backup_start_date AS Start,
backupset.server_name as [Server],
backupset.backup_finish_date AS [End],
DATEDIFF(SECOND, backupset.backup_start_date, backupset.backup_finish_date) AS Duration,
mediafamily.physical_device_name AS Path,
backupset.backup_size AS TotalSize,
backupset.compressed_backup_size as CompressedBackupSize,
encryptor_thumbprint as EncryptorThumbprint,
encryptor_type as EncryptorType,
key_algorithm AS KeyAlgorithm,
CASE backupset.type
WHEN 'L' THEN 'Log'
WHEN 'D' THEN 'Full'
WHEN 'F' THEN 'File'
WHEN 'I' THEN 'Differential'
WHEN 'G' THEN 'Differential File'
WHEN 'P' THEN 'Partial Full'
WHEN 'Q' THEN 'Partial Differential'
ELSE NULL
END AS Type,
backupset.media_set_id AS MediaSetId,
mediafamily.media_family_id as mediafamilyid,
backupset.backup_set_id as BackupSetID,
CASE mediafamily.device_type
WHEN 2 THEN 'Disk'
WHEN 102 THEN 'Permanent Disk Device'
WHEN 5 THEN 'Tape'
WHEN 105 THEN 'Permanent Tape Device'
WHEN 6 THEN 'Pipe'
WHEN 106 THEN 'Permanent Pipe Device'
WHEN 7 THEN 'Virtual Device'
WHEN 9 THEN 'URL'
ELSE 'Unknown'
END AS DeviceType,
backupset.position,
backupset.first_lsn,
backupset.database_backup_lsn,
backupset.checkpoint_lsn,
backupset.last_lsn,
backupset.software_major_version,
mediaset.software_name AS Software,
backupset.is_copy_only,
backupset.last_recovery_fork_guid,
backupset.recovery_model
FROM msdb..backupmediafamily AS mediafamily
JOIN msdb..backupmediaset AS mediaset ON mediafamily.media_set_id = mediaset.media_set_id
JOIN msdb..backupset AS backupset ON backupset.media_set_id = mediaset.media_set_id
JOIN (
SELECT TOP 1 database_name, database_guid, last_recovery_fork_guid
FROM msdb..backupset
WHERE database_name = 'CorruptionChallenge8'
ORDER BY backup_finish_date DESC
) AS last_guids ON last_guids.database_name = backupset.database_name AND last_guids.database_guid = backupset.database_guid AND last_guids.last_recovery_fork_guid = backupset.last_recovery_fork_guid
WHERE (type = 'D' OR type = 'P')
AND is_copy_only='0'
AND backupset.backup_finish_date >= CONVERT(datetime,'1970-01-01T00:00:00',126)
AND mediafamily.mirror='0'
) AS a
WHERE a.BackupSetRank = 1
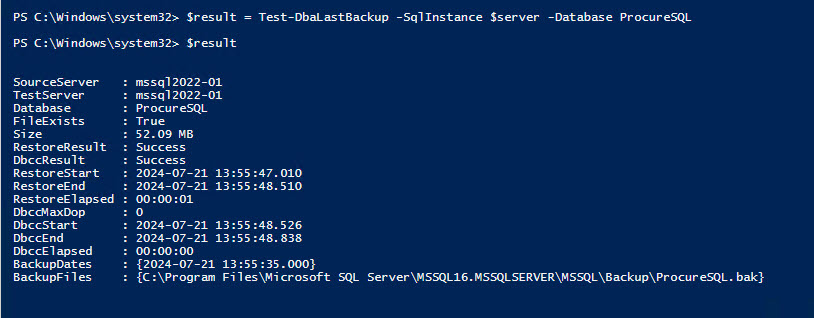
ORDER BY a.Type;The following is a screenshot of the results of validating a database with a good backup and no corruption.
What should I expect with a corrupted database?
Great question! I thought of the same one, so I grabbed a corrupt database from Steve Stedman’s Corruption Challenge and ran the experiment. I will admit my findings were not what I was expecting, either. This is why you shouldn’t take candy from strangers or run scripts without testing them in non-production and validating their results.
After restoring the corrupted database that had been successfully backed up, I performed a manual integrity check to validate that it would fail, as shown below.
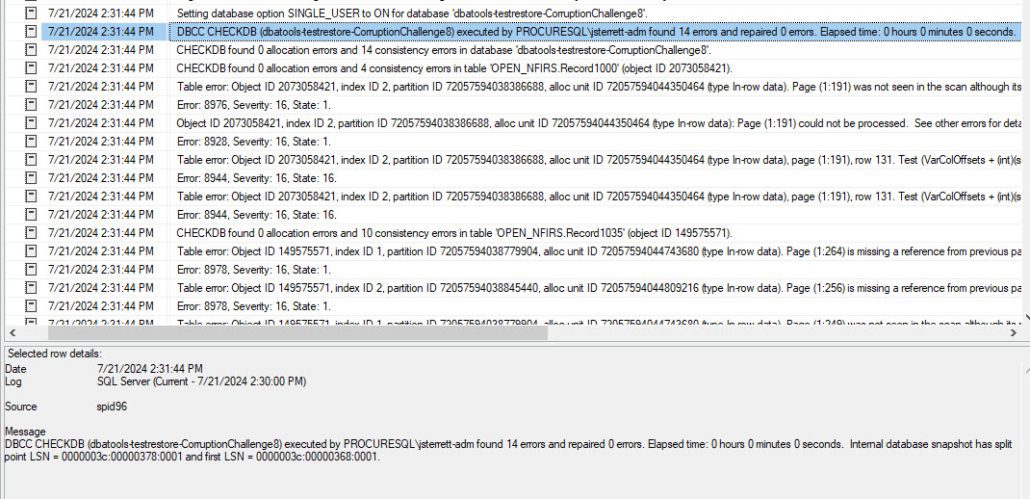
Hopefully, you will have a process or tool to monitor your SQL Server error log and alert you of errors like these. If you duplicate this example, your process or tool will pick up these Severity 16 errors for corruption. I would validate that as well.
Validate SQL Server Backups – PowerShell Results
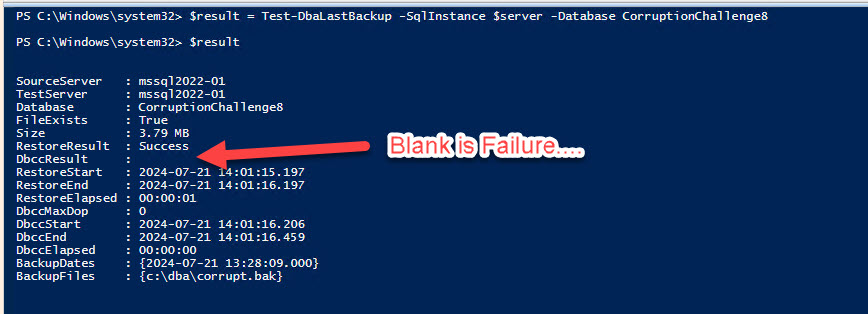
Okay, was I the only one who expected to see Failed as the status for the integrity check (DBCCResult)?
Instead, it’s blank, as I show below. So, when you dump these results back out, make sure to make your check for anything other than Success.
I submitted a bug to DbaTools and post back here with any updates.
Other Questions….
I had some other questions, too, which are answered on the official documentation page for the Test-DbaLastBackup command. I will list them below, but you can review the documentation to find the answers.
- What if I want to test the last full backup?
- What if I want to test the last full and last differential?
- What if I wanted to offload the validation process to another server?
- What if I don’t want to drop the database but use this to restore for non-production testing?
- What if I wanted to do physical only for the integrity check?
- What if I want to do performance testing of my restore process by changing the Max Transfer Size and Buffer Counts?
What questions did we miss that you would like answered? Let us know in the comments.