Today I heard a great analogy, and it inspired this post. Execution plans are like flight plans, there are multiple flight paths that can be taken to get from where you are to your ultimate destination. Some plans are more efficient than others, and we want to use those whenever possible. How can I make sure I am using the plan I want to use? Let’s talk about air traffic control, the Query Store.
What is the Query Store?
Starting in SQL Server 2016, Query Store is a native tool that tracks query execution data including execution statistics and execution plans. It provides graphical views in SSMS and dynamic management views to assist in identifying problem queries.
Reasons to give it a try?
- Knowing what queries are the most expensive
- Seeing all query executions and whether or not they have regressed based on code changes
- Ability to force specific plans for problem queries
Turning it on is a no brainer for many environments, but if your workload is mostly ad hoc you may not see the same benefit as environments that focus more on stored procedure execution
Getting Started
Installation
Since this is a database level setting and not a server level setting, you will have to perform these actions on each database to enable the Query Store. After the initial work to get this enabled, you do have the option to enable it on the model system database and every new database that gets created will also get this setting enabled so you don’t have to worry about doing it later. There are two ways to get Query Store enabled in your environment.
The fastest way to get this enabled on a long list of databases would be to use T-SQL or PowerShell. For PowerShell, I highly recommend utilizing dbatools.io. It’s free and full of amazing documentation.
ALTER DATABASE [StackOverflow2010] SET QUERY_STORE = ON;
ALTER DATABASE [StackOverflow2013] SET QUERY_STORE = ON; 
Set-DbaDbQueryStoreOption -SqlInstance ServerA -Database StackOverflow2010, StackOverflow2013 -State ReadWrite
You can also use the user interface to enable this feature. Right click the database and then open the properties. From here, change the operation mode from off to read write. We will go over additional settings to consider in the section below that can also be updated in this view.

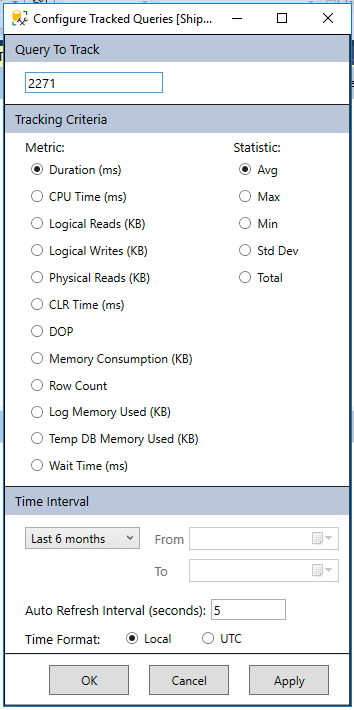
Query Store properties you can change within SSMS GUI to fine-tune your data collection and the amount of impact on performance from your monitoring tool.
Settings to Consider
To implement any of the below settings, you can use the UI like the screenshot above, dbatools for PowerShell, or T-SQL (which I will include below)
Max Size is exactly what it sounds like, a limit to how large you want your query store to grow. Most of the settings below will affect how much space is required, but a good default to work from would be 1GB, adjusting based on the below settings. If the query store runs out of space, it will go from read write to read only and stop gathering query metrics.
Data Flush Interval is used to control how often Query Store goes from memory and gets persisted to disk. When considering this setting, think about how much data you are willing to lose from query store if you have a DR situation arise.
Statistics Collection Interval decides how often to collect metrics. The more often you collect affects how much space you need, but also provides greater levels of granularity when looking into issues in the environment.
Stale Query Threshold controls how often to clean up old data and inactive queries. This setting directly impacts how much space is required for query store.
Query Store Capture Mode determines what queries are captured in query store. Typically this is set to All if you want to capture every query or to Auto if you are ok with SQL ignoring insignificant queries based on execution counts, compile and run times.
Well it’s on, now what?
Stay tuned for additional blogs in my Query Store series to cover basic built in reporting, using query store to assist in tuning, and more advanced features!
The post Query Store 101 appeared first on dbWonderKid.