Have you wanted to build an availability group but didn’t know where to start?
If so, we have discounted SQL Server Availability Group training for you!

Nashville, TN learn how to implement and monitor Always On Availability Group Solutions!
Join us for pre-conference training brought to us by SQL Saturday Nashville! John Sterrett will be presenting a half day precon in Mufreesboro, TN on Thursday, January 11, 2018, from 1:00 pm to 4:30 pm!
SQL Server Availability Group Training in Nashville, TN
In this half-day session, you will learn how to build your first availability group while also learning how availability groups work with other components like active directory, storage, and DNS. You will walk away with a checklist to help your future deployments while also learning how to implement, monitor, troubleshoot and use availability groups.
In this session we will cover:
- Understanding the difference between Availability Groups and Failover Cluster Instances
- Configure Windows Failover Cluster Service (WFCS)
- Understanding Quorum in WFCS
- Pre-staging Active Directory Objects
- Learn how Availability Groups use DNS
- Build Availability Groups
- Implementing Planned Downtime Failovers
- Troubleshoot Common Availability Group Problems
- Proactive monitoring Availability Groups
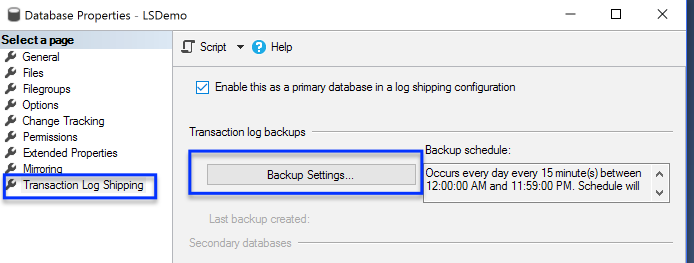
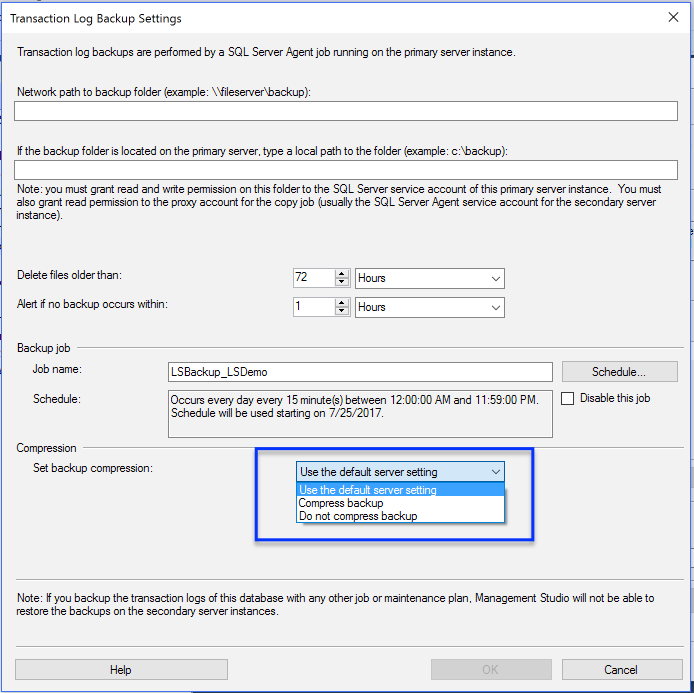
- Backups for your Availability Groups Databases
- Managing Connectivity
- Handling SQL Agent Jobs
- Making SQL Server Reporting Services Highly Available Utilizing Availability Groups
Space is limited so act fast and Register here now!
Come for the SQL Server Availability Group Pre-con and stay for the full day of free SQL training on Saturday!
SQLSaturday is a free training event for Microsoft Data Platform professionals and those wanting to learn about SQL Server, Business Intelligence, and Analytics. Join us on Jan 13, 2018, at Middle Tennessee State University (MTSU), 1301 East Main Street, Murfreesboro, Nashville, Tennessee, 37132.

Nashville SQL Peeps get Your Learn On!