Want to save money, validate performance, and make sure you don’t have errors while migrating to Azure SQL Database, Azure SQL Managed Instance, SQL Server RDS in Amazon AWS? In this video, you will learn how to use the Data Experimentation Assistant to replay and compare your on-premise or cloud SQL Server workloads on-demand. First, you will learn how to capture a workload on-premise or in the cloud. Next, you will master replaying your workload on-demand as needed. Finally, you will do an analysis of comparing a baseline workload and another workload with your changes.
Replay in the Cloud Video
Workload Replay is the Secret Weapon for a Successful Migration to the Cloud
https://procuresql.com/wp-content/uploads/2019/03/Procure-SQL-Automatic-Tuning-1.jpg5631093John Sterrett/wp-content/uploads/2024/05/Data-Architecture-as-a-Service-with-ProcureSQL.pngJohn Sterrett2020-09-11 14:10:322020-09-11 14:10:32Replay in the Cloud
Plan Explorer is another great free tool that should be in every performance tuners toolbelt.
Most people use Management Studio (SSMS) when they are benchmarking queries and improving the performance of their queries. It makes sense because this is the same tool most people use to develop their queries. I have found it to be priceless to have a history log of all my changes. Therefore, I can quickly see how each change impacts the logical reads, duration, CPU, and the execution plan during all of my code changes for the query.
If you are new to benchmarking and improving queries, go ahead and start the video from the beginning. I show you how you can get the actual execution plan, duration, CPU, and reads in SSMS. If you want to see how I track changes via history feature of Plan Explorer, go ahead and skip to 3:36 part in the eight-minute video.
Quickly track the performance changes of your code tuning with Plan Explorer’s history tracking feature.
/wp-content/uploads/2024/05/Data-Architecture-as-a-Service-with-ProcureSQL.png00John Sterrett/wp-content/uploads/2024/05/Data-Architecture-as-a-Service-with-ProcureSQL.pngJohn Sterrett2020-08-04 15:03:322020-08-04 15:03:32Benchmarking Queries with SentryOne Plan Explorer
I am a consultant in Austin who can help make your data go fast, be secure and highly available. When I am engaged in a performance tuning project priority #1 isn’t to make sure your data go faster. Priority #1 is to make sure we get the same result sets while making your data go faster.
Free SQL Data Compare with T-SQL?
There are several tools out there that can be used to compare data. Today, I want to share how you can quickly do this on your own with T-SQL!
Let’s simplify the process. Our goal is to check two temp tables and validate if any of the data is different. This would include inserts, updates, and deletes. For this example, I will just do a dump of Sales.SalesOrderDetail in AdventureWorks into two temp tables as shown below.
SELECT * INTO #Tmp1
FROM Sales.SalesOrderDetail SELECT * INTO #Tmp2
FROM Sales.SalesOrderDetail
Now we shouldn’t see any differences since we used the same table to create both temp tables. We are going to use two different SQL operators to compare these two temp tables while applying some data changes. We will focus on the UNION ALL and EXCEPT operators.
The Power of EXCEPT
Except is an underrated and underused SQL operation. In a nutshell, it will give you the results of the first query that are different from the next query. So, if the data of any column in #tmp1 is different from #tmp2 or if the row doesn’t exist in #tmp2 but is in #tmp1 it will get returned.
SELECT * FROM #Tmp1
EXCEPT SELECT * FROM #Tmp2
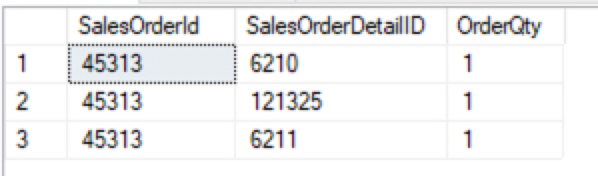
Let’s go ahead and modify a column in #Tmp1 so you can see how this works. We are going to set OrderQty to five when SalesOrderId is 45313 and SalesOrderDetailId is 6210. This will change just one column in one row. We will then select these columns from both temp tables to see the change.
This is how most people would start using T-SQL to identify changes in data.
UPDATE #Tmp1 SET OrderQty = 5 WHERE SalesOrderID = 45313 AND SalesOrderDetailID = 6210 SELECT SalesOrderId, SalesOrderDetailID, OrderQty FROM #Tmp1 WHERE SalesOrderID = 45313 AND SalesOrderDetailID = 6210 SELECT SalesOrderId, SalesOrderDetailID, OrderQty FROM #Tmp2 WHERE SalesOrderID = 45313 AND SalesOrderDetailID = 6210
Data Compare is easy when we know what changed. Data Compare is easy when we know what changed and not much changed. Just select it..
Finding Data Changes The Easy Way
Selecting the two tables is easy if we know what change occurred and there aren’t many changes. This can get complicated quickly. Therefore, if we just want to quickly know if we have differences lets take a look at my goto method using EXCEPT. To make this example easier to read instead of using “SELECT *” I will just focus on columns that are changing. In a real example, I would want to know if any columns changed.
SELECT SalesOrderId, SalesOrderDetailID, OrderQty FROM #Tmp1
EXCEPT SELECT SalesOrderId, SalesOrderDetailID, OrderQty FROM #Tmp2
Data Compare using EXCEPT quickly lets us see that we had a data change
If an insert or a column change occurs in #tmp1 we will see it in our EXCEPT SQL statement. This isn’t true if the change is only in #tmp2.
For example, an insert in #tmp2 or delete in #tmp1 would not be shown. To see this we would have to switch the temp tables in the EXCEPT clause as shown below.
INSERT INTO #tmp2 (SalesOrderId, ProductID, SpecialOfferID, OrderQty, UnitPrice, UnitPriceDiscount,LineTotal, rowguid, ModifiedDate)
VALUES (45313, 1, 3, 1,1.25,0,
1.25*1, NEWID(), GETDATE()) DELETE FROM #Tmp1
WHERE SalesOrderID = 45313 AND SalesOrderDetailID = 6211 SELECT SalesOrderId, SalesOrderDetailID, OrderQty FROM #Tmp1
EXCEPT SELECT SalesOrderId, SalesOrderDetailID, OrderQty FROM #Tmp2
/* We will now see our insert and delete */
SELECT SalesOrderId, SalesOrderDetailID, OrderQty FROM #Tmp2
EXCEPT SELECT SalesOrderId, SalesOrderDetailID, OrderQty FROM #Tmp1
Our first EXEMPT clause only shows the update that occurred in #tmp1. The delete in #tmp1 and insert in #tmp2 cannot be seen because the data doesn’t exist in #tmp1.
Our Second EXEMPT shows the insert in #tmp2, delete in #tmp1 and update on #tmp1 because the column is different on #tmp2
Our first except shows us data in #tmp1 that is not in #tmp2 because the OrderQty column changed in #tmp1. The second EXCEPT shows us data in #tmp2 that isn’t in #tmp1 because of our insert into #tmp2 and also our delete from #tmp1 would be found in #tmp2 but not #tmp1.
UNION ALL for the Win!
To wrap this up now we can include a UNION ALL operation between the two EXCEPT operations. This would get us any data changes to the columns selected from the temp tables.
SELECT SalesOrderId, SalesOrderDetailID, OrderQty FROM #Tmp1
EXCEPT SELECT SalesOrderId, SalesOrderDetailID, OrderQty FROM #Tmp2
UNION ALL
SELECT SalesOrderId, SalesOrderDetailID, OrderQty FROM #Tmp2
EXCEPT SELECT SalesOrderId, SalesOrderDetailID, OrderQty FROM #Tmp1
UNION ALL and EXCEPT for the free Data Compare Win! Quickly shows rows that are different between the two tables.
Typically, I need to verify is the data before and after is the same. This is a quick and easy way to get that answer. Now I know you might want to take this to the next level. You might be thinking how do I just get the unique key for the table and columns that changed. I will leave that as an exercise for you.
The following are five tips for working remotely that I learned over the years from working remotely with large companies like DELL, RDX and now even as a leader of a consulting company that focuses on making our customer’s data fast, secure and highly available.
Manage Your Schedule
Manage your schedule do not let it manage you! Technically not a remote working tip but I noticed this was very important for me when I transitioned from working in an office to working from home. I love my Full Focus Planner it is a tool that helps me get the most out of my day, week, quarter and year!
Full Focus Planner is my favorite tip for working remotely. It is my go-to tool for scheduling and planning efficiently.
In short, I changed from focusing on tasks to focusing on my schedule. My tasks are now like blocks of legos and my schedule is the board for my legos. This visually allowed me to understand two things. One, what am I committed too and how much time do I have to accomplish what’s important. Second, what is my three most important tasks that needed my focus today and how does my current schedule allow me to focus on them. Maybe it doesn’t and I need to make some changes. Weekly I get to pause and see how I am heading on my quarterly and yearly goals and also evaluate if they still make sense.
Exercise throughout the day.
The most important thing you can do now is to take care of your health. I lost over 70 pounds in a year by simply altering my eating habits and setting my Fitbit to alarm at the fifty-minute mark of the hour so I could walk for 10 minutes. It helped me quickly get my 10k steps. If I had a meeting that did not require me to use my computer I would walk during the meeting.
Bonus: wait for the fifty-five-minute mark of the hour and walk for ten minutes. You will get your Fitbit step credits for both hours.
Communicate More Not Less
In my first year working remotely as an employee, I learned that I could actually communicate better remotely than when I was in the office. To be successful in any role communication is critical. Instead of having a group around me all having different needs I was able to utilize technology like messaging, video conference, screen sharing (Microsoft is giving FREE six months for Teams to do all of these) to not only get tasks done faster but also train more people while I was working. That said, it all started with promptly returning messages, emails, calls, and voice mails. Even if the response was to say, this request is in my queue. We will get you an update tomorrow.”
Work like you never left the office
Good work habits working in the office can transition easily to working remotely. Keep things as simple as possible. Did you maintain a typical daily schedule for starting and ending work? If so keep those hours. Regardless communicate with everyone to know how and when its best to communicate with you. Take some breaks just like you would in the office. Just make them more productive and valuable to your day to day needs.
You Are Not Alone
Working remotely does not mean you are on an island all by yourself. One of the best things I think you can do during the transition is to ask your colleges or managers for feedback on how the situation is working out. Do they see any changes in the value you are providing in your role?
Hopefully, these tips for working remotely are helpful for anyone who is making the transition to working remotely. Let me know your thoughts about these tips or questions you might have in the comments below.
https://procuresql.com/wp-content/uploads/2020/03/rOe5KnPWRomLNFMd5Vidag-scaled-1.jpg25601920John Sterrett/wp-content/uploads/2024/05/Data-Architecture-as-a-Service-with-ProcureSQL.pngJohn Sterrett2020-03-25 16:47:432025-09-09 21:45:23Five Tips for Working Remotely
This month’s T-SQL Tuesday is hosted by Tracy Boggiano. Tracy invites us all to write about adopting Query Store. Today, I wanted to share my favorite but a very unique way I use the Query Store for Workload Replays.
You can read more about the invite in detail by clicking on the T-SQL Tuesday logo in this post.
Today, I wanted to talk about my least favorite part of replaying workloads. It’s having an extended event or server-side trace running during a workload replay only so we can compare the results at a query-level when the replay is finished. Now, this might seem like a trivial thing but when you have workloads over 10k batch requests/sec this can consume terabytes of data quickly. The worst part is waiting to read all the data, slice and dice the data for analysis.
Starting with SQL Server 2016 there is a better and faster way to go! You can replace your extended event or server-side trace with Query Store captured data. Today, I will show you how to use the Query Store for the same purpose.
Different Settings
Keep in mind our goal here is very different from the typical use case for using the Query Store. We want to capture metrics for all the queries executed during a workload replay. Nothing more and nothing less.
If we have the runtime results for multiple replays we can then easily compare the workload performance between the workload replays.
Most of our changes from the regular Query Store best practices are shown below:
Max Size (MB) – Need to make sure there is enough space to capture your whole workload. This size will vary by how much workload is being replayed.
Query Store Capture Mode set to All. Normally, not ideal, but remember we want to capture metrics for our whole workload being replayed.
Size Based Cleanup Mode set Off – Yup, we don’t want to lose our workload data that is capture until we persist in our ideal form. More on this later.
The Capture Process
Now, this is where you would use Database Experimentation Assistant (DEA), Distributed Replay or some other process to replay your consistent workload in an isolated non-production environment. This subject we will cover in another future post. For now, we will just have two replays called “Baseline” and “Change”. This simulates a baseline replay with no schema changes and then another change replay with a change introduced in the schema.
To capture our workload we just enable the Query store with our settings mentioned above and also clear out the query store right before our workload replay starts to help ensure we are just capturing our workload.
USE [master]
GO
ALTER DATABASE [YourDatabase] SET QUERY_STORE = ON
GO
ALTER DATABASE [YourDatabase] SET QUERY_STORE (OPERATION_MODE = READ_ONLY, MAX_STORAGE_SIZE_MB = 10000, QUERY_CAPTURE_MODE = AUTO, SIZE_BASED_CLEANUP_MODE = OFF)
GO
ALTER DATABASE [YourDatabase] SET QUERY_STORE CLEAR
GO
Stop Capturing Query Store Data
Once your replay is finished we will want to disable the query store from writing data into the query store. We want the least amount of non-workload data inside of the Query Store when we are using it for the sole purpose of comparing workloads.
USE [master]
GO
ALTER DATABASE [YourDatabase] SET QUERY_STORE (OPERATION_MODE = READ_ONLY)
GO
Prepare Query Store Data for Long-Term Analysis
Now for smaller workloads, one might be happy with utilizing DBCC CLONEDATABASE to have a schema-copy of their workload with Query Store data persisted. This is perfectly fine. With bigger workloads being captured I have noticed there are ways to improve the performance of query store when doing analysis of the query store data. For example, clustered columnstore indexes can be very helpful for performance and compacity. Therefore, I like to have a schema for each replay and import the data. The following is a quick example of setting up a schema for a “baseline” replay and a “change” replay.
CREATE DATABASE [DBA]
GO
use [DBA]
GO
CREATE SCHEMA Baseline;
GO
CREATE SCHEMA Compare;
GO
Next, we will import our captured data from our baseline replay that’s in our read-only query store database. I also like to have a baked-in aggregate of metrics for reads, writes, duration and CPU at the query level.
use [YourDatabase]
GO
/* Load Data */
SELECT * INTO DBA.Baseline.query_store_runtime_stats FROM sys.query_store_runtime_stats; SELECT * INTO DBA.Baseline.query_store_runtime_stats_interval from sys.query_store_runtime_stats_interval; select * INTO DBA.Baseline.query_store_plan from sys.query_store_plan; select * INTO DBA.Baseline.query_store_query
from sys.query_store_query; select * INTO DBA.Baseline.query_store_query_text
from sys.query_store_query_text;
/* Addition for SQL 2017 */
select * INTO DBA.Baseline.query_store_wait_stats from sys.query_store_wait_stats use [DBA]
GO SELECT SUM(Count_executions) AS TotalExecutions,
SUM(Count_executions*avg_duration) AS TotalDuration,
SUM(Count_executions*avg_logical_io_reads) AS TotalReads,
SUM(Count_executions*avg_logical_io_writes) AS TotalWrites,
SUM(count_executions*avg_cpu_time) AS TotalCPU,
query_hash
INTO Baseline.QueryResults
FROM Baseline.query_store_runtime_stats rs
JOIN Baseline.query_store_plan p ON rs.plan_id = p.plan_id
JOIN Baseline.query_store_query q ON p.query_id = q.query_id
GROUP BY q.query_hash
Next, we would reset the database to our starting position and add our query store settings as mentioned above in this blog post and replay or workload again. This time, we would dump our data into the “change” schema
use [YourDatabase]
GO
/* Load Data */
SELECT * INTO DBA.Compare.query_store_runtime_stats FROM sys.query_store_runtime_stats; SELECT * INTO DBA.Compare.query_store_runtime_stats_interval from sys.query_store_runtime_stats_interval; select * INTO DBA.Compare.query_store_plan from sys.query_store_plan; select * INTO DBA.Compare.query_store_query
from sys.query_store_query; select * INTO DBA.Compare.query_store_query_text
from sys.query_store_query_text; select * INTO DBA.Compare.query_store_wait_stats from sys.query_store_wait_stats use [DBA]
GO SELECT SUM(Count_executions) AS TotalExecutions,
SUM(Count_executions*avg_duration) AS TotalDuration,
SUM(Count_executions*avg_logical_io_reads) AS TotalReads,
SUM(Count_executions*avg_logical_io_writes) AS TotalWrites,
SUM(count_executions*avg_cpu_time) AS TotalCPU,
query_hash
INTO Compare.QueryResults
FROM Compare.query_store_runtime_stats rs
JOIN Compare.query_store_plan p ON rs.plan_id = p.plan_id
JOIN Compare.query_store_query q ON p.query_id = q.query_id
GROUP BY q.query_hash
Comparing Workload Results
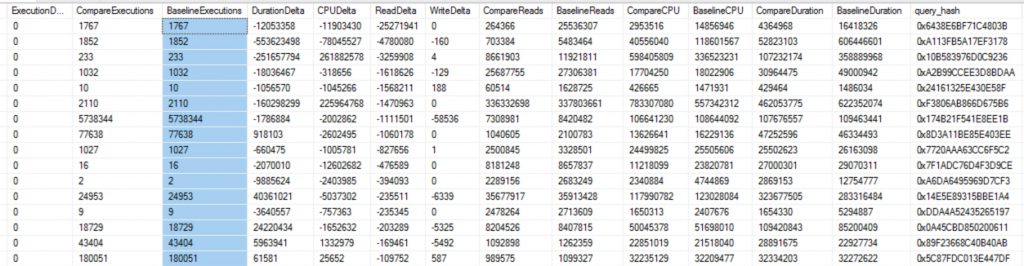
Now that we have our two workloads imported we can now compare to see how the workload changed per query. I will break this down into two quick steps. First, get deltas per query. Second, get totals for how many times a query might be different in the query store. More on this a little later in the post.
/* Query Store Results */
use [DBA]
GO SELECT DISTINCT c.TotalExecutions - b.TotalExecutions AS ExecutionDelta,
c.TotalExecutions AS CompareExecutions,
b.TotalExecutions AS BaselineExecutions,
c.TotalDuration - b.TotalDuration AS DurationDelta,
c.TotalCPU - b.TotalCPU AS CPUDelta,
c.TotalReads - b.TotalReads AS ReadDelta,
c.TotalWrites - b.TotalWrites AS WriteDelta,
c.TotalReads AS CompareReads,
b.TotalReads AS BaselineReads,
c.TotalCPU AS CompareCPU,
b.TotalCPU AS BaselineCPU,
c.TotalDuration AS CompareDuration,
b.TotalDuration AS BaselineDuration,
c.query_hash
--q.query_sql_text
INTO #CTE
FROM Baseline.QueryResults b
JOIN Compare.QueryResults c ON b.query_hash = c.query_hash select COUNT(query_sql_text) AS QueryCount, MAX(query_sql_text) query_sql_text, MIN(query_id) MinQueryID, qsq.query_hash
INTO #Compare
from Compare.query_store_query qsq
JOIN Compare.query_store_query_text q ON qsq.query_text_id = q.query_text_id where qsq.is_internal_query = 0
GROUP BY query_hash select COUNT(query_sql_text) AS QueryCount, MAX(query_sql_text) query_sql_text, MIN(query_id) MinQueryID, qsq.query_hash
INTO #Baseline
from Baseline.query_store_query qsq
JOIN Baseline.query_store_query_text q ON qsq.query_text_id = q.query_text_id where qsq.is_internal_query = 0
GROUP BY query_hash select cte.*
, a.QueryCount AS Compare_QueryCount
, b.QueryCount AS Baseline_QueryCount
, a.MinQueryID AS Compare_MinQueryID
, b.MinQueryID AS Baseline_MinQueryID
, a.query_sql_text
FROM #CTE cte JOIN #Compare a on cte.query_hash = a.query_hash
JOIN #Baseline b on cte.query_hash = b.query_hash
WHERE 1=1
AND ExecutionDelta = 0
ORDER BY ReadDelta ASC
Query Store for Workload Replays
Workload Replays compared down to the query execution level is priceless!
Lessons Learned Along the Way!
Initially, working with the query store I thought query_id was going to be my best friend. I quickly learned that my old friend query_hash is more helpful for multiple reasons. One, I can easily compare queries between different replays. That’s right now all workload replays get you the same query_id even when the workload is the exact same being replayed. Two, I can compare them with different databases as well. Finally, query_hash is very helpful with ad-hoc workloads as I can aggregate all the different query_ids that have the same query hash.
/wp-content/uploads/2024/05/Data-Architecture-as-a-Service-with-ProcureSQL.png00John Sterrett/wp-content/uploads/2024/05/Data-Architecture-as-a-Service-with-ProcureSQL.pngJohn Sterrett2020-03-11 00:36:382020-03-11 00:36:38Query Store for Workload Replays
I recently spoke at a conference and was asked what is the easiest way to import databases to Azure SQL Database. Therefore, I wanted to share how I do this with DBATools.io. You can use the same code to just export if you need a local copy of an Azure SQL database as well.
Import-Module dbatools -Force
<# Variables #>
$BackupPath = "C:\Demo\AzureSQL\Bacpac" #folder location for backups
$SourceInstance = "sql2019\sql2016"
$DBName = "AdventureWorksLT2012"
$AzureDestInstance = "procuresqlsc.database.windows.net"
$DBNameDest = $DBName <# backpac options for import and export #>
$option = New-DbaDacOption -Type Bacpac -Action Export
$option.CommandTimeout = 0 $option2 = New-DbaDacOption -Type Bacpac -Action Publish
$option2.CommandTimeout = 0 <# The following assums Azure SQL Database exists and is empty Azure will create database by default if it doesn't exist #>
$bacpac = Export-DbaDacPackage -Type Bacpac -DacOption $option -Path `
$BackupPath -SqlInstance $SourceInstance -Database $DBName Publish-DbaDacPackage -Type Bacpac -SqlInstance `
$AzureDestInstance -Database $DBNameDest -Path $bacpac.path ` -DacOption $option2 -SqlCredential username
What Is my Performance Tier?
Great question, as of 3/3/2020 if the database in Azure SQL Database does not exist then it will be created. When its created the following database uses the default performance tier. This is General Purpose (Gen5) with 2 vCores.
The default cost of a new Azure SQL Database is 371.87 per month.
How to create cheaper databases
Great question, you can import databases to Azure SQL Database cheaper using PowerShell. It is as simple as using the Azure PowerShell Module. The following example below I use my existing Azure SQL Database server and I end up creating a new database with the “S0†tier.
You got all the nuts and bolts to generate a script that can migrate all your databases on an instance. Then you can import databases to Azure SQL Database in one loop.
Today I wanted to cover how you can grant the least privilege required to stop, start or restart an Azure VM. This is also a fun great example of how you can create custom Azure Security Roles too. That’s right, we are killing two birds with one stone today.
Why Should you create a custom Role?
Where possible I like to grant security towards resource groups. Therefore, let’s assume we got multiple VM’s built for the developer group to do some testing. You want to grant people access to start, restart or stop any VM in that group. We can then grant access to the resource group to our custom role. As VMs come in and out of the resource group they would inherit our custom group.
Now, you might be wondering why don’t I just give them the “Contributor†role or the “Virtual Machine Contributor†role and be on our way? Well, if you were to do this on a resource group you just gave access to create VM’s and a whole lot more.
Least privileged roles are your best friend. Today, you will see they are also not that hard to create either.
How do we create custom roles?
Great question, first you need to identify what tasks do we need the role to complete. In our case, you have to be able to see a VM in order to take any action against the VM. Then we want to start, stop (deallocate), and restart the VM. Digging through IAM. I found the following security options.
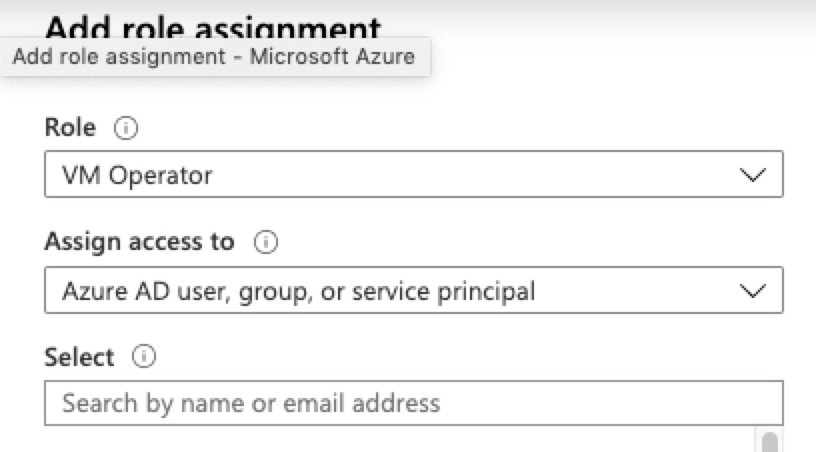
Now, we can create our custom JSON text file that we will then import using Azure CLI. Below you will find a sample JSON file to build our custom security role. You will need to add your subscription id(s). You can also change your name and description you would see in the Azure Portal.
Now that we are ready to go with our custom security role in a JSON file. We can then utilize Azure CLI to log in to the tenant and import our security role. First, we will log in to Azure with CLI as shown below.
az login --username <myEmailAddress> -t <customerTenantId-or-Domain>
Now we will load our saved JSON file. After a few minutes, we should then see our new security role in the Azure portal.
az role definition create --role-definition IAMRole-VMOperator.json
Now you can grant access to your custom role just like you would with any other role in Azure.
Hello everyone, this is John your Austin SQL Server Consultant here and today I am going to answer a question that comes up often so I wanted to blog about it for everyone. The question of the day is where can I download the previous SQL Server Updates?
The History towards Updates
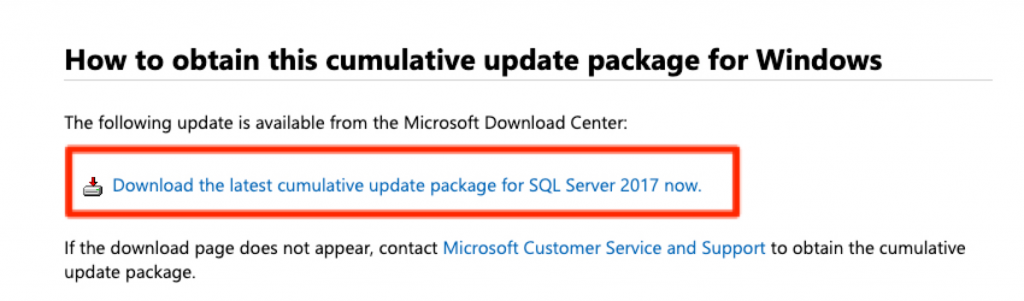
Back in the day when we were young but not a kid anymore there were service packs and cumulative updates. We could download these separately and all of the updates were easy to find. Now today, if you click on a KB article to download an update you get pointed to the latest update as shown below.
How far is My SQL Server on Updates?
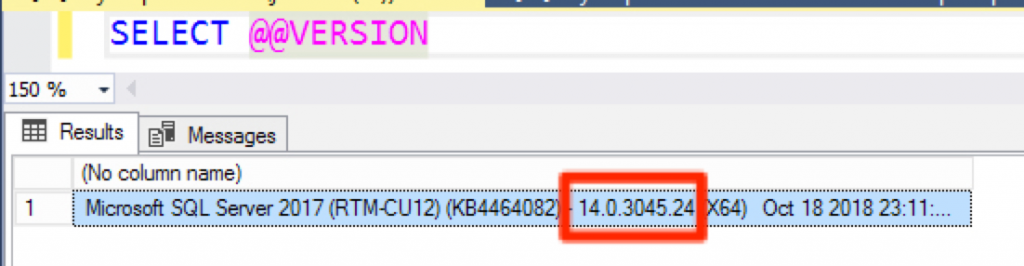
This is also another great question. My favorite place to find all the history of updates toward SQL Server is the SQL Server Build List Blog. You can cross-reference this towards your version by running the following query below.
You can use SELECT @@VERSION to get your current version number.
I fully get exactly why Microsoft is trying to point everyone to the latest update. Normally, it makes perfect sense but let’s take a look at today Jan 9th, 2020. I am planning to update SQL Server 2017 to CU17. Its been out for two months. Today CU18 is released and if I wasn’t careful I would have downloaded a different update than expected.
SQL Server Blog List is a great resource for finding a list of all SQL Server Updates
Getting a previous SQL Server Update
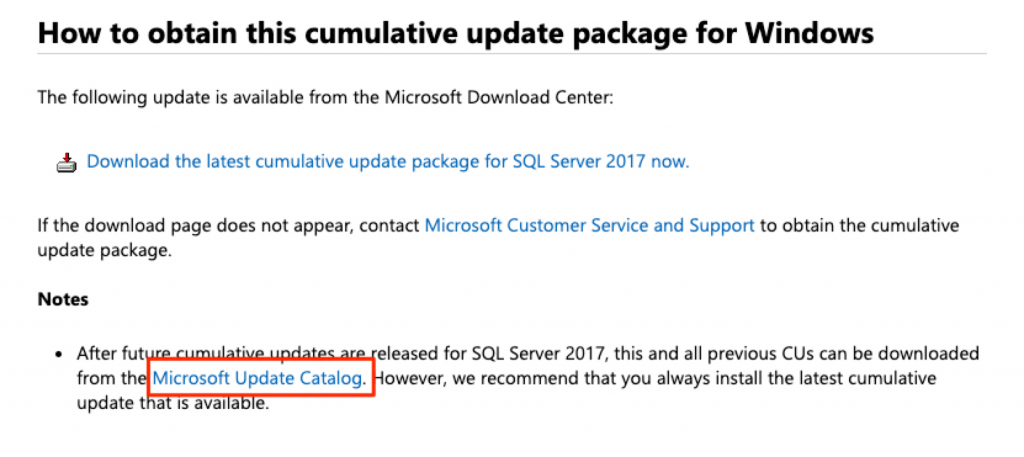
So, on to the solution. It’s actually an easy one but also one that is easy to overlook as well. Let’s go back to the new standard update page for SQL Server updates.
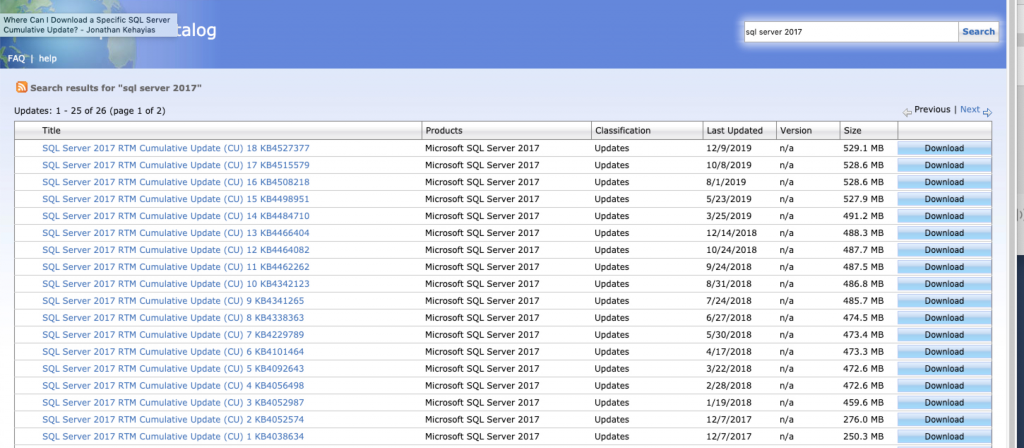
That is right, the Microsoft Update Catalog is your best friend to find all your updates for Microsoft products including SQL Server. You can search for the product you want. For example, in this case, I am looking for SQL Server 2017 and can see all the previous updates for SQL Server.
All the SQL Server Updates can be found in the Microsoft Update Catalog
If you enjoyed this tip and found it helped make sure to join our newsletter so you can enjoy more free tips, tricks, and video demos.