Hello everyone! This is your SQL Server Consultant in Austin, TX and due to some posts on twitter about SQL PASS recordings costing $999 I wanted to share some of my favorite places to find free SQL Server training videos. I hope this helps make your data fast, secure and highly available in 2020 and beyond!
Attending conferences is nice but free recorded sessions are priceless!
Those who know me know I love music. I especially love the underground non-mainstream content. Therefore, my first recommendation is UserGroup.TV. As of December 27th, there are 127 videos tagged as SQL Saturday alone. Shawn goes around to almost every Tech conference he can find and brings his rig and records sessions for the community.
Are you in love with the new pop singles? Wish you could hear them before they hit the radio? If you like your tech like your music than Microsoft Ignite is for you. Every year Microsoft puts on a conference called, Ignite. This conference is usually where Microsoft will break its cutting edge tech. My favorite thing about the conference is that the content is available online for free. Midway through the page, you can search through the massive collection of free recorded sessions.
Next up, is the consistent greatest hits. Almost every session is a banger! This reminds me of my favorite Microsoft Data Platform conference. This is SQLBits and yes, their video content is also available for FREE.
/wp-content/uploads/2024/05/Data-Architecture-as-a-Service-with-ProcureSQL.png00John Sterrett/wp-content/uploads/2024/05/Data-Architecture-as-a-Service-with-ProcureSQL.pngJohn Sterrett2019-12-27 15:59:022019-12-27 15:59:02Free SQL Server Training Videos
Microsoft made SQL Server 2019 Generally Available this week we want to share some videos and code examples of our favorite new features. Most of these will make your code go faster without any code changes!
We have been testing SQL Server 2019 for months and hope you enjoy these features as much as we do!
https://procuresql.com/wp-content/uploads/2019/12/5-game-changers-with-sql-server-2019-1.gif11John Sterrett/wp-content/uploads/2024/05/Data-Architecture-as-a-Service-with-ProcureSQL.pngJohn Sterrett2019-11-05 22:06:242019-11-05 22:06:245 Game Changers with SQL Server 2019
In this tip, we want to go over the fundamentals of Row-Level-Security for a database table. Don’t let your data be vulnerable to data breaches. It makes sense to secure the data all the way down to the row level. Common real-world examples include multi-tenant applications, sensitive data, and data that could be broken down into territories or regions.
How Do Does Row-Level Security Work?
This is a great question. It works off of a table value function to layout the security check and a policy that implements the security function for a table.
Let’s check it out! First, we will create two tables. The Sales table that holds the sales data and the SalesReps table which holds the Many to Many relationships on who can see whos sales. In this example, the Manager will see all rows, SalesLead will see SalesLead and Sales1 rows.
Note: In this example by default, Sales3 won’t be able to see its own data. Neither would sysadmin or database owner. Therefore you will need to make sure your security function allows a failsafe for seeing data for the people who should be able to touch all the data for the table.
USE [master]
GO
IF EXISTS (SELECT * FROM sys.databases WHERE name LIKE 'RLS_Demo')
BEGIN
DROP DATABASE RLS_Demo
END
CREATE DATABASE RLS_Demo
GO
USE [RLS_Demo]
GO
/* Create database users for testing */
CREATE USER Manager WITHOUT LOGIN;
CREATE USER SalesLead WITHOUT LOGIN;
CREATE USER Sales2 WITHOUT LOGIN;
CREATE USER Sales3 WITHOUT LOGIN;
CREATE TABLE Sales
(
OrderID int,
SalesRep sysname,
Product varchar(30),
Qty int
);
/* Define who can more than one SalesRep's orders */
CREATE TABLE SalesResp
( SalesRepLead sysname,
SalesRep sysname,
PRIMARY KEY (SalesRepLead, SalesRep)
)
/*Sales1 is TeamLead*/
INSERT INTO SalesResp (SalesRepLead, SalesRep)
VALUES ('SalesLead', 'SalesLead')
INSERT INTO SalesResp (SalesRepLead, SalesRep)
VALUES ('SalesLead', 'Sales2')
INSERT INTO SalesResp (SalesRepLead, SalesRep)
VALUES ('Sales2', 'Sales2')
/* Note no records for Sales3 in our Many to Many lookup */
INSERT INTO Sales VALUES (1, 'SalesLead', 'Pirates Hat', 5);
INSERT INTO Sales VALUES (2, 'SalesLead', 'Terrible Towel', 2);
INSERT INTO Sales VALUES (3, 'SalesLead', 'Clemente Jersey', 4);
INSERT INTO Sales VALUES (4, 'Sales2', 'Pirates Hat', 2);
INSERT INTO Sales VALUES (5, 'Sales2', 'Clemente Jersey', 5);
INSERT INTO Sales VALUES (6, 'Sales2', 'Terrible Towel', 5);
INSERT INTO Sales VALUES (4, 'Sales3', 'Pirates Hat', 1);
INSERT INTO Sales VALUES (5, 'Sales3', 'Clemente Jersey', 1);
INSERT INTO Sales VALUES (6, 'Sales3', 'Terrible Towel', 2);
GRANT SELECT ON Sales TO Manager;
GRANT SELECT ON Sales TO SalesLead;
GRANT SELECT ON Sales TO Sales2;
GRANT SELECT ON Sales TO Sales3;
/* RLS not in place. Should see all 9 rows */
SELECT * FROM Sales;
Now let’s look at the meat and potatoes of Row-Level Security. This would be the function and the policy that bounds the row-level security to a table.
/* Keep all your Row Level Security in its own securable schema */
CREATE SCHEMA Security;
GO
/* Note no failsave for sysadmin and Sales3 doesn't exist in SalesResp table either */
CREATE FUNCTION Security.fn_securitypredicate(@SalesRep AS sysname)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN SELECT 1 AS fn_securitypredicate_result
WHERE @SalesRep IN (SELECT SalesRep FROM dbo.SalesResp WHERE SalesRepLead = USER_NAME() )
OR USER_NAME() = 'Manager';
CREATE SECURITY POLICY SalesFilter
ADD FILTER PREDICATE Security.fn_securitypredicate(SalesRep)
ON dbo.Sales
WITH (STATE = ON);
GRANT SELECT ON security.fn_securitypredicate TO Manager;
GRANT SELECT ON security.fn_securitypredicate TO SalesLead;
GRANT SELECT ON security.fn_securitypredicate TO Sales2;
You should notice there is no logic to help sysadmin users see the data in the table. Therefore just like Sales3 now any sysadmin wouldn’t see any data.
/* DB owner shows no rows due to RLS */
EXECUTE AS USER = 'dbo'
SELECT * FROM Sales;
REVERT;
EXECUTE AS USER = 'SalesLead';
SELECT * FROM Sales;
REVERT;
EXECUTE AS USER = 'Sales2';
SELECT * FROM Sales;
REVERT;
EXECUTE AS USER = 'Manager';
SELECT * FROM Sales;
REVERT;
/* Notice no rows as security function returns zero rows from lookup table */
EXECUTE AS USER = 'Sales3';
SELECT * FROM Sales;
REVERT;
In this scenario, to allow Sales3 to see its own sales data we just need to insert a record into the SalesReps table as shown below and we are good to go.
INSERT INTO SalesResp (SalesRepLead, SalesRep)
VALUES ('Sales3', 'Sales3')
EXECUTE AS USER = 'Sales3';
SELECT * FROM Sales;
REVERT;
Now if you want to remove row-level security or make some modifications to the function used in the policy all you have to do is drop the security policy then the function.
/* Clean up */
DROP SECURITY POLICY SalesFilter
DROP FUNCTION Security.fn_securitypredicate
Your Homework!
Figure how to implement row-level security to benefit your business! Also, go ahead and figure out how to add a failsafe so sysadmins can still see all the data like they normally would.
I am not sure why but sometimes I am glutting for punishment. Maybe its why I try every backup and restore solution I can get my hands on? While Microsoft has done an amazing job at building the best relational database engine Azure Backup for SQL Server Virtual Machines has some architecture problems. In this post, I will showcase things you need to focus on, problems, and workarounds for your initial run with an Azure Backup for SQL Server VMs.
What’s Azure Backup for SQL Server Virtual Machines (VMs)?
If you take a look at Azure Backup they added functionality for backing up SQL Server databases inside an Azure VM. This seems like a really cool feature. Let’s use the same technology we use to backup our VM’s to also backup our databases. You know the whole one-stop-shop for your disaster recovery needs. Comes with built-in monitoring and it also eliminates the struggle some people have with setting up certificates, encryptions, purging old backups in blob storage, backups and restores from blob storage. It is really nice to also have a similar experience as restoring Azure SQL Databases as well.
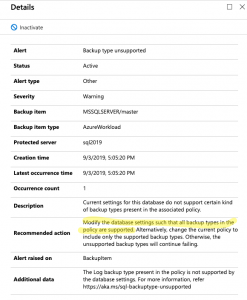
Unfortunately, the product doesn’t work as expected at this point in time. I would expect any database backup tool to be able and backup the system databases by default without any customization. Therefore, Last night I setup my first Azure Backup for SQL Server Virtual Machines in the Backup Vault and this morning you can see my results below.
Azure Backup for SQL Server VM’s gets 0/3 system databases backed up by default
Now we will dig into concerns and initial problems with Azure Backup for SQL Server Virtual Machines (VMs).
Automatically Backup New Databases
Having the ability to backup new databases automatically is taken for granted. So much, that I noticed that Azure Backup for SQL Server VM’s will not automatically backup new databases for you. That’s right. Make sure you remember to go in and detect and select your new database every time you add a database or you will not be able to recover.
Azure Backup for SQL Server VM’s has an interesting feature called Autoprotect. This should automatically backup all your databases for you. Unfortunately, this does not work. Yes, I double-checked by enabling autoprotect for a VM and I added a new database. The database didn’t get backed up so I had to manually add the database.
Simple Recovery Problems
Looking into the failures for my system database backups I noticed something interesting in the log for the master database. It looks like you will get errors with the only SQL Server backup policy created by default. The reason is the policy includes transactional log backups and as you know its impossible to take a transactional log backup if your database utilizes the simple recovery model. Now, most backup tools know how to roll with databases in simple and full recovery.
Looks like Azure Backup for SQL Server VM’s is not one of these tools that easily allow you to mix databases utilizing both simple and full recovery models.
Yup, simple recovery model is no bueno..
So, how do we get around this? It is not too hard. Just create a new backup policy that does not include transactional log backups and assign it to your databases that utilize the simple recovery model.
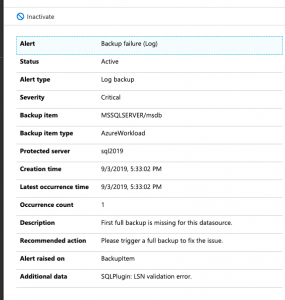
Transactional Log Backup Problems
So, what happens when you try to take a transactional log backup of a database that doesn’t have a full backup? It fails. This is by design. If you try to take a log backup in this scenario with T-SQL it will fail as well. That said, several 3rd Party open source backup solutions like my recommended one can gracefully handle this for you. It can take a full backup instead of the log backup. I have grown to expect this behavior.
Here is what you will see in the logs of Azure Backup for SQL Server VM’s.
You have to force a full backup or wait until the scheduled full backup occurs. Yuck!
So, the workaround here is simple. You can force a backup. This will start the process of allowing your schedule log backups to work as designed. You could also wait until the scheduled full backup runs but know this means you will not have point in time recovery until that full backup runs. There should be an option to perform a full backup instead of a transactional log backup if a full backup does not exist. This would prevent the transactional log scheduled backups from failing.
Things to Know!
Azure Backup for SQL Server VM’s pricing goes off of storage as well as instances of SQL. By default, compression is not used for the SQL Server Backups. You will most likely want to make sure you enable this to save some money.
There are many documented limitations that we didn’t cover in this blog post. Some shocking ones to me are SQL Server Failover Cluster Instances and don’t configure backup for more than 50 databases in one go
/wp-content/uploads/2024/05/Data-Architecture-as-a-Service-with-ProcureSQL.png00John Sterrett/wp-content/uploads/2024/05/Data-Architecture-as-a-Service-with-ProcureSQL.pngJohn Sterrett2019-09-04 21:25:312019-09-04 21:25:31Azure Backup for SQL Server VMs
Procure SQL has achieved Gold Partner Status with Microsoft for its Cloud and Database Platform capabilities.
As a member of Microsoft’s Gold-Certified Partnership, we’ll
have access to Microsoft’s newest products and services. We’ll work with
Microsoft in the development, training and implementation of new technology and
database solutions.
Procure SQL’s philosophy is that fast databases are critical
for your company to deliver on your promises to your customers. Our Remote
Database Management Services help you make good on those promises.
“We are very excited
to be part of the Microsoft Gold-Certified Partner,†said John Sterrett, CEO at
Procure SQL. “Being part of the Microsoft Gold-Certified Partner Program will
give us even more tools in our toolbox when managing our client’s database and
cloud environments.â€
About Procure SQL
Procure SQL offers a variety of DBA services, including:
100% onshore DBAs
Senior level talent on every account
Full SQL Server Assessment and road mapping
4 times the value of a senior DBA for a 1â„4 of
the cost
We offer packages for as little as 20 hours of expert Remote DBA experience a month. Learn more at here.
While not all implicit conversions are equal implicit conversions matter. For example, just this week I ran into a trivial code change that caused some severe regression in performance. One simple filter change caused a query to consume 227 million reads compared to 212 reads. What did the filter do? Well, it forced an implicit conversion.
In this blog post you will learn what is an implicit conversion, how to identify it, and also how do you find the implicit conversion leading to the highest amount of reads in the query store.
What is a SQL Server Implicit Conversion?
This is a great question. The answer is when SQL Server optimizer has to convert data in a column to match the type you are using in your query. For example, if you had a column that was an Integer and you decided to filter off of a string “varchar” variable. ORM’s like Entity Framework is notoriously known for this. You would end up forcing an implicit conversion. This will force the optimizer to read every value in the column and cast it so the column can then be filtered based off your variable or another column that doesn’t match the same data type.
Let’s look at an example. Yes, this is exactly similar to the example mentioned in the first paragraph that consumed 227 million reads. We are just going to simplify it down for you with a copy of the AdventureWorks modified database.
SalesOrderID column is an INT, not VARCHAR. We are going to filter with a VARCHAR data type using the LIKE operator as shown below.
SELECT [SalesOrderID]
,[SalesOrderDetailID]
,[CarrierTrackingNumber]
,[OrderQty]
,[ProductID]
,[SpecialOfferID]
,[UnitPrice]
,[UnitPriceDiscount]
,[LineTotal]
,[rowguid]
,[ModifiedDate]
FROM [AdventureWorks2012].[Sales].[SalesOrderDetailEnlarged]
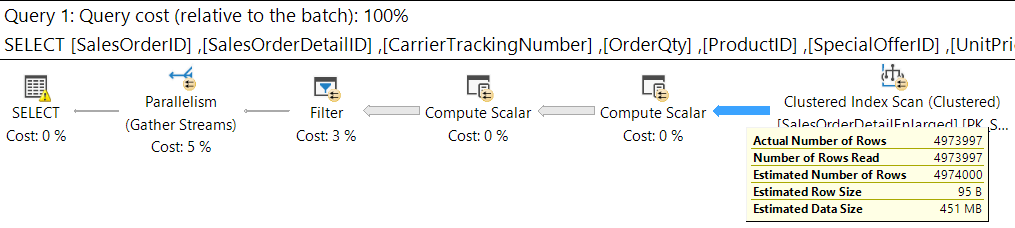
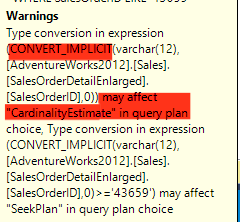
WHERE SalesOrderID LIKE '43659'
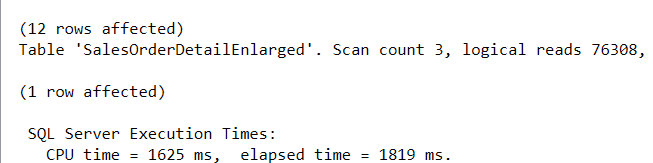
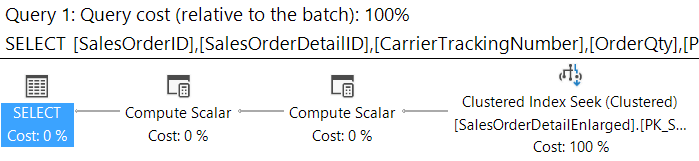
This will produce the following execution plan and statistics which is not ideal at all. We will get a warning for the implicit conversion and also go parallel scanning the whole table due to this conversion.
A SQL Server Implicit Conversion Forces a Table Scan
SQL Server Implicit Conversions causing the whole table to be read.
The following is statistics for our implicit conversion
How to fix Implicit Conversions in SQL Server
Now that we know how to identify an implicit conversion I bet you might be wondering how do you resolve them? They usually come in two flavors. First, the columns do not match data types on a join. Second, the parameter or literals data type does not match with the column. Today, we will focus on the second time in the code below.
The only thing we change in our code is the type of filter.
SELECT [SalesOrderID]
,[SalesOrderDetailID]
,[CarrierTrackingNumber]
,[OrderQty]
,[ProductID]
,[SpecialOfferID]
,[UnitPrice]
,[UnitPriceDiscount]
,[LineTotal]
,[rowguid]
,[ModifiedDate]
FROM [AdventureWorks2012].[Sales].[SalesOrderDetailEnlarged]
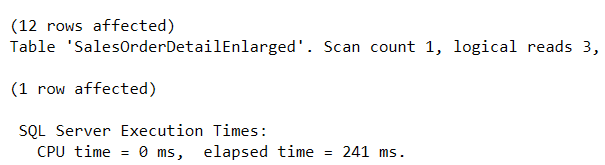
WHERE SalesOrderID = 43659
The literal parameter matches with the column data type.Gone from 76k reads to 3!
How do I get Implicit Conversions from the Query Store?
Now that you understand implicit conversions you might wonder how do I find them? Well, hopefully, you are on SQL Server 2016 or higher and can query the execution plans in query store. If not, check out Jonathan Kehayias example to find implicit conversions in the plan cache.
Disclaimer: Plan cache will only have execution plans that are still in memory. Query store will only have execution plans that are in the query store. Also, I added variables for the start date, end date, and top offenders. Performance milage will vary based on how your query store is configured and used. run the query below at your own risk!
DROP TABLE IF EXISTS #plans
DROP TABLE IF EXISTS #tmp1
DROP TABLE IF EXISTS #tmp2
DROP TABLE IF EXISTS #finalplan
GO
DECLARE @StartDate datetime = dateadd(d,-1, getdate()),
@EndDate datetime = getdate(),
@TopStmts INT = 1000
SELECT TOP (@TopStmts)
SUM(qrs.count_executions) * AVG(qrs.avg_logical_io_reads) as est_logical_reads,
SUM(qrs.count_executions) AS sum_executions,
AVG(qrs.avg_logical_io_reads) AS avg_logical_io_reads,
SUM(qsq.count_compiles) AS sum_compiles,
qsp.plan_id
INTO #tmp1
FROM sys.query_store_query qsq
JOIN sys.query_store_plan qsp on qsq.query_id=qsp.query_id
JOIN sys.query_store_runtime_stats qrs on qsp.plan_id = qrs.plan_id
WHERE qrs.first_execution_time >= @StartDate
AND qrs.last_execution_time <= @EndDate
group by qsp.plan_id
ORDER BY est_logical_reads DESC
SELECT cte.*, TRY_CAST (qsp.query_plan AS XML) AS xml_query_plan
INTO #tmp2
FROM #tmp1 cte
JOIN sys.query_store_plan qsp ON cte.plan_id = qsp.plan_id
SELECT #tmp2.*
INTO #plans
FROM #tmp2;
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
DECLARE @dbname SYSNAME
SET @dbname = QUOTENAME(DB_NAME());
;WITH XMLNAMESPACES
(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT p.est_logical_reads, p.sum_executions, p.avg_logical_io_reads, p.plan_id
, stmt.value('(@StatementText)[1]', 'varchar(max)') AS SQLStmt,
t.value('(ScalarOperator/Identifier/ColumnReference/@Schema)[1]', 'varchar(128)') AS SchemaName,
t.value('(ScalarOperator/Identifier/ColumnReference/@Table)[1]', 'varchar(128)') AS TableName,
t.value('(ScalarOperator/Identifier/ColumnReference/@Column)[1]', 'varchar(128)') AS ColumnName,
ic.DATA_TYPE AS ConvertFrom,
ic.CHARACTER_MAXIMUM_LENGTH AS ConvertFromLength,
t.value('(@DataType)[1]', 'varchar(128)') AS ConvertTo,
t.value('(@Length)[1]', 'int') AS ConvertToLength,
p.xml_query_plan
INTO #finalplan
FROM #plans p
CROSS APPLY xml_query_plan.nodes('/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple') AS batch(stmt)
CROSS APPLY stmt.nodes('.//Convert[@Implicit="1"]') AS n(t)
CROSS APPLY stmt.nodes('.//PlanAffectingConvert[@ConvertIssue="Cardinality Estimate"]') AS ce(pt)
JOIN INFORMATION_SCHEMA.COLUMNS AS ic
ON QUOTENAME(ic.TABLE_SCHEMA) = t.value('(ScalarOperator/Identifier/ColumnReference/@Schema)[1]', 'varchar(128)')
AND QUOTENAME(ic.TABLE_NAME) = t.value('(ScalarOperator/Identifier/ColumnReference/@Table)[1]', 'varchar(128)')
AND ic.COLUMN_NAME = t.value('(ScalarOperator/Identifier/ColumnReference/@Column)[1]', 'varchar(128)')
WHERE t.exist('ScalarOperator/Identifier/ColumnReference[@Database=sql:variable("@dbname")][@Schema!="[sys]"]') = 1
SELECT fp.est_logical_reads, fp.sum_executions, fp.avg_logical_io_reads, fp.plan_id,
qsq.query_id, qsq.query_hash, fp.SQLStmt, fp.SchemaName, fp.TableName,
fp.ColumnName, fp.ConvertFrom, fp.ConvertTo, fp.ConvertFromLength, fp.ConvertToLength, fp.xml_query_plan
FROM #finalplan fp
JOIN sys.query_store_plan qsp ON fp.plan_id = qsp.plan_id
JOIN sys.query_store_query qsq ON qsp.query_id = qsq.query_id
ORDER BY fp.est_logical_reads DESC
Have you ever noticed that execution plans changed? Is your performance suffering due to the change? If so, Automatic Plan Correction is for you. In our previous blog post, we identified scalar function improvements,parameter sniffing and data skew. In this post, we are going to show you how SQL Server 2017 can automatically help improve your performance. This is done by changing executions plans to improve your performance.
How does Automatic Plan Correction work?
Great question. Go ahead and watch the short video below to see for yourself.
If you found this page you most likely either found yourself in the middle of a SQL Server parameter sniffing and/or data skew issue and have no idea how to get yourself out of this hole. In the eight-minute video below we go over exactly what parameter sniffing and data skew is and how you can identify it on your own.
SPOILER ALERT: Parameter sniffing is mostly an amazing thing that saves tons of CPU cycles. Like many DBA tasks, this usually only gets attention when expectations are not met. Most likely you have these issues in your database without even knowing it. See a real-world case where data skew was resolved with a customer using SQL Server 2017 without changing any code.
Learn how to identify parameter sniffing and data skew and fix it on your own.
How do we fix SQL Server parameter sniffing?
Now that you know what parameter sniffing and data skew is our next blog post will go over using Query Store and Automatic Tuningto enhance your performance automatically or manually. This will resolve queries that regressed due to parameter sniffing.
https://procuresql.com/wp-content/uploads/2018/09/Procure-SQL-Should-We-Compress-SQL-Server-Backups-1.jpg5601454John Sterrett/wp-content/uploads/2024/05/Data-Architecture-as-a-Service-with-ProcureSQL.pngJohn Sterrett2019-04-17 16:58:392019-04-17 16:58:39What is SQL Server parameter sniffing and data skew?
Have you ever had a query that runs frequently start to randomly go slower? We all have and without the proper tools and knowledge, this can be hard to figure out because there can be so many different reasons. In this blog post, our goal is to make your query optimization in SQL Server a lot better and easier for you.
How does a SQL Server query get proccessed?
This is a great question. All queries get put into a queue if they are not available to run. If there are any available schedulers then the query will start processed. We call this the RUNNING state. If the RUNNING query needs to pause to obtain any required resource like pages from disk or is blocked this query will have SUSPENDED state. Once the required pause is no longer needed, the query status will go back into the queue and its status will now be “RUNNABLE”. This queue is first in first out (FIFO) and once the query moves up the queue and a schedule is free the query is back in motion and has the “RUNNING” status again. This circle can be repeated multiple times until the query execution completes.
Hopefully, our flow process of the status of a query will make sense below.
How do we see the waits for my query?
Now that you understand how a query waits. Lets go ahead and look at how we recommend reviewing this data. Before SQL Server 2017 you had to a bit of work with extended events and dynamic management views. Now we can use our best friend, the query store.
In this video below you will learn how to figure out what waits occurred when your query was executed inside of SSMS without writing a single line of code.
Lets look and see why your query is running slow…
What are your thoughts about getting quick access to waits going on for your queries? Got aditional questions? Let us know in the comments section down blow.
Can I get the demo code?
We know some of you love to replay demos and we like to give you the code to do so when you have free time. If you have any questions with the demo below fill free to throw your questions our way.
USE [master];
GO
ALTER DATABASE [WideWorldImporters]
SET QUERY_STORE (OPERATION_MODE = READ_WRITE,
DATA_FLUSH_INTERVAL_SECONDS = 60,
QUERY_CAPTURE_MODE = ALL, /* For demo purposes.
most likely don't want to capture all in prod */
INTERVAL_LENGTH_MINUTES = 1);
GO
USE [WideWorldImporters];
GO
DBCC DROPCLEANBUFFERS; -- For demo to get PAGEIOLATCH waits
ALTER DATABASE CURRENT SET QUERY_STORE CLEAR ALL;
/* Verify Clean Starting Point */
select * from sys.query_store_plan
select * from sys.query_store_query
select * from sys.query_store_runtime_stats
select * from sys.query_store_wait_stats /* New in SQL 2017 */
GO
USE [WideWorldImporters];
GO
/* Load all records from disk into memoery
because we dropped clean buffers */
SELECT * FROM Sales.Invoices
/* 102 records */
SELECT * FROM Sales.Invoices
WHERE CustomerID = 832
/* Create locking example.
Begin explicit transaction
but don't commit or rollback yet */
BEGIN TRANSACTION
UPDATE Sales.Invoices
SET DeliveryInstructions = 'Data Error'
WHERE CustomerID = 832
-- Hold off on rolling back until after the block
/* Now back in another window,
wait a few seconds and then
execute the following statement */
USE [WideWorldImporters];
GO
SELECT COUNT(DeliveryInstructions)
FROM Sales.Invoices
WHERE CustomerID = 832
-- After a few seconds - roll back the other transaction
/* Now Rollback and show other window has data */
ROLLBACK TRANSACTION
/* Flushes the in-memory portion of the Query Store data to disk.
https://docs.microsoft.com/en-us/sql/relational-databases/system-stored-procedures/sp-query-store-flush-db-transact-sql?view=sql-server-2017
*/
USE [WideWorldImporters];
GO
EXECUTE sp_query_store_flush_db;
GO
/*
Look at all queries in QS using Sales.Invoices.
Notice our UPDATE is missing??
We Rolled it BACK
*/
SELECT [q].[query_id], *
FROM sys.query_store_query_text AS [t]
INNER JOIN sys.query_store_query AS [q]
ON [t].query_text_id = [q].query_text_id
WHERE query_sql_text LIKE '%Sales.Invoices%';
/* get the query_id from statement above
use it to get the plan_id so we can look at its waits */
declare @queryID bigint = 7
SELECT *
FROM sys.query_store_plan
WHERE query_id = @queryID;
/*Get all waits for that plan. */
begin
declare @planid int = 7
select * from sys.query_store_runtime_stats_interval
SELECT * --wait_category_desc, avg_query_wait_time_ms
FROM sys.query_store_wait_stats
WHERE plan_id = @planid AND
wait_category_desc NOT IN ('Unknown')
ORDER BY avg_query_wait_time_ms DESC;
end
GO
/* Make sure you filter for time intervals needed */
declare @planid int = 7
SELECT wait_category_desc, avg_query_wait_time_ms
FROM sys.query_store_wait_stats
WHERE plan_id = @planid AND
wait_category_desc NOT IN ('Unknown')
ORDER BY avg_query_wait_time_ms DESC;
GO
/* Look at all waits in system */
select * from sys.query_store_wait_stats
https://procuresql.com/wp-content/uploads/2018/09/Procure-SQL-RTO-RPO-1.jpg5611076John Sterrett/wp-content/uploads/2024/05/Data-Architecture-as-a-Service-with-ProcureSQL.pngJohn Sterrett2019-04-10 04:41:092019-04-10 04:41:09Why is my SQL Server query slower than normal?
With SQL Server 2017 Microsoft improved the journey towards making your code go faster without any code changes required by your developers. SQL Server 2019 gives you more of this super cool black magic.
Today, we are going to show you the details of why scalar functions executions are changing and how you can make Scalar functions run faster if you are not on SQL Server 2019 (SPOILER ALERT: It will require some code changes)
Why are Scalar Functions Silent Performance Killers?
Scalar functions are silent performance killers because before SQL Sever 2019 you wouldn’t see them in execution plans or using set statistics which is how most people benchmark a queries performance. Below we have a video going over Scalar Functions and how to see the silent performance killer.
Hello SQL Server User, meet your silent but deadly performance killer.
How does SQL Server 2019 Make this better?
This is a great question. I am glad you asked.
If you saw the video above you know that scalar functions do row by row processing and you can see in the Profiler trace that the GetMaxProductQty_Scalar function was executed for all 504 rows in the product table.
In SQL Server 2019, the row by row processing will go to set based logic when possible. This is shown in the next video below in great detail.
Can you help me find more information on Scalar Function changes with SQL 2019?
YES! The following are some great extra reference articles I would highly recommend reviewing.
Aaron Bertrand who works with SentryOne has a great write up as well.
Can I have the source code and play with the demo?
Yes, I strongly encourage it. In fact, if you have any questions going through the demo and have questions feel free to ask me questions.
USE [master];
GO
ALTER DATABASE [AdventureWorks2012]
SET QUERY_STORE (OPERATION_MODE = READ_WRITE,
/* For demo purposes. Most likely don't want these settings in production! */
DATA_FLUSH_INTERVAL_SECONDS = 60,
QUERY_CAPTURE_MODE = ALL,
INTERVAL_LENGTH_MINUTES = 1);
GO
USE [AdventureWorks2012];
GO
DBCC DROPCLEANBUFFERS; -- For demo to get PAGEIOLATCH waits
ALTER DATABASE CURRENT SET QUERY_STORE CLEAR ALL;
/*
How does scalar functions work before SQL Server 2019?
Lets see...
*/
USE [master]
GO
ALTER DATABASE [AdventureWorks2012] SET COMPATIBILITY_LEVEL = 120
GO
USE [AdventureWorks2012]
GO
select @@SPID
set statistics io on
set statistics time on
GO
/*** Makes demo go faster
CREATE INDEX idx_test ON Sales.SalesOrderDetailEnlarged (ProductID)
INCLUDE (OrderQty)
WITH (DATA_COMPRESSION = PAGE, ONLINE=ON)
***/
/* CleanUp - Remove functions for the demo
DROP IF EXISTS was added in SQL 2016
*/
USE [AdventureWorks2012]
GO
DROP FUNCTION IF EXISTS GetMaxProductQty_Scalar
DROP FUNCTION IF EXISTS GetMaxProductQty_Inline
GO
/* Now the fun begins... */
USE [AdventureWorks2012]
GO
CREATE FUNCTION GetMaxProductQty_Scalar
(
@ProductId INT
)
RETURNS INT
AS
BEGIN
DECLARE @maxQty INT
SELECT @maxQty = MAX(sod.OrderQty)
FROM Sales.SalesOrderDetailEnlarged sod
WHERE sod.ProductId = @ProductId
RETURN (@maxQty)
END
/* Clear all pages from memory
WARNING: Do not do this in production..
This gives us a senario where no pages or plans are in memory. */
CHECKPOINT
DBCC DROPCLEANBUFFERS;
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;
/* New in SQL Server 2016 and SQL Azure.
This removes plan cache for the database you are in.
Can use this to replace DBCC FREEPROCCACHE which would
remove plan cache for ALL databases */
/* TODO: LOAD PROFILER - Show ROW BY ROW Function Calls */
/* Row By Row Processing - Scalar Function */
SELECT
ProductId,
dbo.GetMaxProductQty_Scalar(ProductId) As MaxQty
FROM Production.Product
ORDER BY 2 DESC
/* Where is function calls? Didn't we also hit SalesOrderDetailEnlarged?
(504 row(s) affected)
Table 'Product'. Scan count 1, logical reads 4, physical reads 1, read-ahead reads 2, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1750 ms, elapsed time = 1958 ms.
*/
/** Lets look at SQL Server 2019 CTP 2.4 Inline Scalar Functions. **/
USE [master]
GO
ALTER DATABASE [AdventureWorks2012] SET COMPATIBILITY_LEVEL = 150
GO
/* Clear all pages from memory
WARNING: Do not do this in production..
This gives us a senario where no pages or plans are in memory. */
USE [AdventureWorks2012]
GO
CHECKPOINT
DBCC DROPCLEANBUFFERS;
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;
GO
/* TODO: LOAD PROFILER - Show ROW BY ROW Function Calls */
/* Row By Row Processing - Scalar Function */
USE [AdventureWorks2012]
GO
SELECT
ProductId,
dbo.GetMaxProductQty_Scalar(ProductId) As MaxQty
FROM Production.Product
ORDER BY 2 DESC
GO
/**** We now SEE SalesOrderDetailEnlarged in plan and Set Statistics IO.
WE DIDN'T SEE THIS BEFORE SQL SERVER 2019 ****
(504 rows affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderDetailEnlarged'. Scan count 504, logical reads 11930, physical reads 2, read-ahead reads 8341, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Product'. Scan count 1, logical reads 4, physical reads 1, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 2156 ms, elapsed time = 2494 ms.
*/
/*** HOW CAN WE MAKE THIS BETTER
if we are NOT on SQL SERVER 2019? ***/
USE [master]
GO
ALTER DATABASE [AdventureWorks2012] SET COMPATIBILITY_LEVEL = 140
GO
/*
Utilize a table value function
instead of scalar function where possible.
*/
USE [AdventureWorks2012]
GO
CREATE FUNCTION GetMaxProductQty_Inline
(
@ProductId INT
)
RETURNS TABLE
AS
RETURN
(
SELECT MAX(sode.OrderQty) AS maxqty
FROM Sales.SalesOrderDetailEnlarged sode
WHERE sode.ProductId = @ProductId
)
GO
CHECKPOINT
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
/*
WHAT is APPLY?
https://technet.microsoft.com/en-us/library/ms175156(v=sql.105).aspx
The APPLY operator allows you to invoke a table-valued function
for each row returned by an outer table expression of a query.
The table-valued function acts as the right input and the outer
table expression acts as the left input. The right input is
evaluated for each row from the left input and the rows produced
are combined for the final output.
*/
SELECT p.ProductId,
MaxQty
FROM Production.Product p
CROSS APPLY dbo.GetMaxProductQty_Inline(p.ProductId) tvf
ORDER BY 2 DESC
/*
(504 rows affected)
Table 'Product'. Scan count 2, logical reads 40, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderDetailEnlarged'. Scan count 3, logical reads 8230, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 3015 ms, elapsed time = 2018 ms.
*/
CHECKPOINT
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
/* In this case, we can just join against the two tables */
SELECT p.ProductId, MAX(sod.OrderQty)
FROM Sales.SalesOrderDetailEnlarged sod
RIGHT JOIN Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.ProductID
ORDER BY 2 DESC
/* (504 rows affected)
Table 'Product'. Scan count 3, logical reads 40, physical reads 1, read-ahead reads 14, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderDetailEnlarged'. Scan count 3, logical reads 8226, physical reads 1, read-ahead reads 8317, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 3048 ms, elapsed time = 2122 ms.
*/
/* Index to improve - Columnstore Index */
USE [AdventureWorks2012]
GO
CREATE NONCLUSTERED COLUMNSTORE INDEX nccidx_SalesOrderDE on Sales.SalesOrderDetailEnlarged (ProductID, OrderQty)
GO
USE [AdventureWorks2012]
GO
CHECKPOINT
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
GO
SELECT ProductId,
MaxQty
FROM Production.Product
CROSS APPLY dbo.GetMaxProductQty_Inline(ProductId) MaxQty
ORDER BY 2 DESC
/*
(504 rows affected)
Table 'SalesOrderDetailEnlarged'. Scan count 2, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 8251, lob physical reads 13, lob read-ahead reads 30209.
Table 'SalesOrderDetailEnlarged'. Segment reads 6, segment skipped 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Product'. Scan count 1, logical reads 4, physical reads 1, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 47 ms, elapsed time = 724 ms.
*/
/*** Does Non Clustered Columnstore index change anything
With SQL 2019?
We wouldn't be doing this if it didnt ;-)
****/
USE [master]
GO
ALTER DATABASE [AdventureWorks2012] SET COMPATIBILITY_LEVEL = 150
GO
/* Clear all pages from memory
WARNING: Do not do this in production..
This gives us a senario where no pages or plans are in memory. */
USE [AdventureWorks2012]
GO
CHECKPOINT
DBCC DROPCLEANBUFFERS;
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;
GO
USE [AdventureWorks2012]
GO
SELECT
ProductId,
dbo.GetMaxProductQty_Scalar(ProductId) As MaxQty
FROM Production.Product
ORDER BY 2 DESC
/* YOUR MILAGE MIGHT VERY....
(504 rows affected)
Table 'Worktable'. Scan count 504, logical reads 14546904, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderDetailEnlarged'. Scan count 2, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 4006, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderDetailEnlarged'. Segment reads 6, segment skipped 0.
Table 'Product'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 31203 ms, elapsed time = 31640 ms.
*/
/* ---------- > CLEANUP < ----------- */
USE [AdventureWorks2012]
GO
DROP FUNCTION IF EXISTS GetMaxProductQty_Scalar
DROP FUNCTION IF EXISTS GetMaxProductQty_Inline
DROP INDEX IF EXISTS idx_SalesOrderDE_ProductID_Include1 on Sales.SalesOrderDetailEnlarged
DROP INDEX IF EXISTS nccidx_SalesOrderDE on Sales.SalesOrderDetailEnlarged
GO