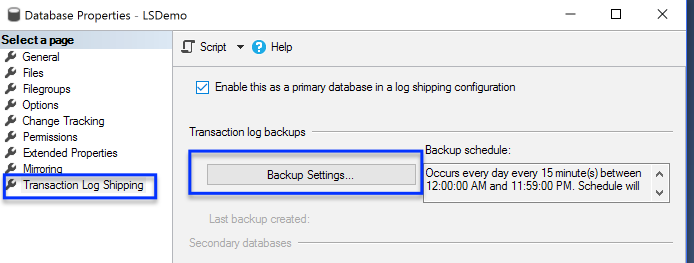
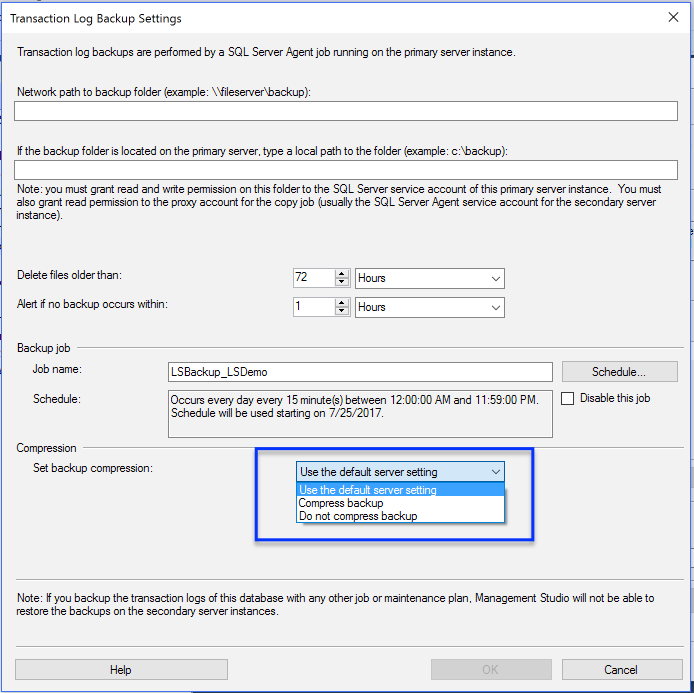
In my opinion, automation will enhance DBAs. It will allow DBAs to provide more value to the business.Good DBAs will be fine. If you are a DBA with ten years of DBA experience who just repeats year one ten times, this might be a different story for a different blog post. Therefore, automation enhances the Good DBAs careers just like the sync button enhances turntablists but the sync button doesn’t replace good turntablists’ careers.
Follow along to see if you agree or disagree. I look forward to seeing your feedback in the comments section on this topic.

Some of my good friends know I have a passion for DJing on the ones and twos. A subset of those friends know I took a job in high school just so I could buy two Technics 1200s and records. In my free time, I started taking an online DJ Masterclass and it quickly jumped out to me that the sync button for turntablists, club DJs (see just like DBAs there are several different types of DJs) isn’t much different from automation for good DBAs. The sync button is a way to automate the tedious task of making sure two different songs are played at the same speed so they could be mixed together. In the past few years, I started to hear buzz that automation will replace DBAs so I wanted to write a blog post providing more details into a recent tweet of mine.
What is this sync Button You Speak Of? How does it relate to DBAing?
Going back to my high school days for a second. One of the core fundamentals of being a turntablist is using beat matching to keep the dance floor going as you transition from one song to another song. It took me months to learn this fundamental skill. I had to learn how to measure BPM (beats per minute) to see if the songs could even mix together. I had to learn beats (think of pages) and bars (think of extents) and learn how to mix the songs on the same beat on right bars. I had to learn how to adjust the speed of each of the two records to make the BPMs match on my own. When mixing, I had to make sure the two records stayed on beat during the mix. Syncing records isn’t the hard part of DJing, it’s just a tedious part.
Today, most DJ software packages have a sync button so this process can be automated. Now we can hit the sync button and the BPMs will match almost all of the time. What would you do if you didn’t learn the basics and relied on the sync button and the BPM for your song is wrong, or worse, your venue doesn’t have the sync button? I think this would be similar to having corruption occur and not knowing the basics behind DBCC CHECKDB, Backups and Restores. You won’t be keeping people on the dance floor for long, or have a successful DBA Career.
 If you don’t know the basics, you will rely on the software and have no other options if and when the software doesn’t automatically work for you.
If you don’t know the basics, you will rely on the software and have no other options if and when the software doesn’t automatically work for you.
I Love Automation, I have loved it for years!
I love automation because it allows me to automate tedious tasks and focus on ones I love and which provide value. For now, I will talk about automation in general and will focus a bit later on some new features with SQL Server that help automate things.
I have been using automation as a tool in my toolbox for almost my whole DBA career. I have given talks on Getting Started with PowerShell for DBAs; my first PASS Member Session was on utilizing Policy-Based Management to automate basic health checks. You can even use 3rd party tools or custom scripts like this, this, this, this, or this to help with some automation. Just make sure they work for you and your environment. I have seen a nice automated SQL Server installer built a very long time ago that used JavaScript before JavaScript was cool. I bet it actually started with JScript (Insert painful JScript vs JavaScript memories from my web development days).
The language used doesn’t matter, what matters is what the process does.
At the same time, I have actually seen a software service provider application that in my opinion didn’t monitor transactional log backups correctly, yikes. I mention this not to scare you, but to remind you that you need to know the basics to know if an automation process works for your needs. If you don’t know what the automated process is supposed to do how do you know it is doing it correctly? Using the wrong automation tool, or using the tools incorrectly, could be very hurtful to your career. This looks a lot like the sync button for DJing to me. Automation tools/scripts also evolve and change so this isn’t a set it and forget it thing either, in my humble opinion.
It has been a tool in their toolbag for quite a while, not a new thing. DBAs also know how to leverage it as a great tool instead of seeing it as a new tool that replaces their jobs. BIML is a great automation tool for Business Intelligence (BI) Developers. Does BIML automate good BI Developers out of their jobs? Nope. Does it help them automate so they can focus more time toward high-value tasks and get more things done? Yep, it sure does.
If automation is new to you as a DBA, or maybe you are starting out as a DBA, I suggest checking out some well-proven open source tools in a non-production environment. If you try to test out automation, several solutions include options to script out but not execute the tasks. This can be very helpful for learning (just like I used the script feature in SSMS to learn a lot about T-SQL behind the GUI). If you are looking for a place to start, I highly recommend dbatools.io . It’s amazing to look at all the things one could do with this single tool.
Can Self-Tuning Databases Completely Automate DBA Tuning?
Performance tuning is one of my favorite parts of being a DBA; therefore, there is no way I would skip talking about some of the great enhancements that allow SQL Server to tune your own environment in Azure SQL Database and the box product. It’s purely amazing to see some of the new cutting-edge tuning features that, in my opinion, are game changers that will help Microsoft further separate themselves from all other database management systems on the market.
Don’t hold your breath while you try to read about some of these great performance improvements provided just since SQL Server 2014. There is cardinality estimator changes, auto tuning for adding and removing indexes, adaptive plan changes, query store, resumable index rebuilds, heck good old Database Tuning Advisor gets better and wait for it…. Automate Tuning. Don’t take my word for it that these features will be amazing. Go check out Lance Tidwell’s about some of these new features in his PASS Summit talk in November. Actually, take a second to read his abstract. Notice the following, “We will also look at some of the pitfalls and potential issues that can arise from these new features.” I find it interesting that it looks like Automated Tuning and other features might not safely automate all your tuning needs.
I don’t foresee Self-Tuning Databases being able to self-tune everything.
A friend of mine Joey D’Antoni wrote a great blog post recently on Self-Tuning Databases. Let’s go by this statement in his blog post, “I am sure this would take years and many versions to come into effect.” Let’s fast forward and assume this is fully in effect including even multiple features outside of execution plan changes. I will throw in an example, Artificial Intelligence that could find several common known T-SQL Anti-Patterns and rework the code for all of them so the optimizer friendly version executes.
Let’s take a look at why I do not foresee automated tuning fully replacing Performance Tuning DBAs.
The way people implement business processes with technology will prevent automated tuning from fixing everything in your environment. It could be hardware, database design, could be bad coding, bad anti-patterns in code, misuse of ORMs, ORMs struggling to your data model, etc. My point is, I don’t see performance tuning getting completely automated to the point where performance tuning skills will be obsolete. I am not alone, another good friend of mine, Grant Fritchey writes, “Finally, despite the fact of adaptive plans and automated regressions, you are still writing code that NO amount of automation can fix.”
Will the Cloud Automate DBAs Out of their Jobs?
The cloud will not automate DBAs out of their jobs. First, let me start with the fact that I love the cloud. I write about Azure, and I give presentations on Azure SQL Database. Azure SQL Database has grown a lot over the years and almost has all the same features as the box product. Microsoft has also added great additional features to differentiate themselves from their competitors like Query Performance Insight, Automated Tuning to add and remove indexes, Geo-Replication and more to help make Azure SQL Database my favorite platform as a service offering. Soon, Azure Managed Instances of SQL Server will even make admin tasks easier for DBAs as they will be able to apply their skills directly with fewer changes like the box product.
Even though it is a fantastic time to leverage cloud services not all companies are going to put all of their critical data there. Many are still using SQL Server 2005. Some still work with mainframes. Using the same logic, shouldn’t those DBAs have been automated away years ago?
migrations to multiple cloud providers and even helped clients spin up their own cloud environments that they offer as a service, while also providing them Remote DBA Services as well.
I know what you’re thinking.Why do I need DBA help if I am in the cloud?
If someone is using a managed service for their databases in a platform as a service model (PaaS) like Amazon RDS or Azure SQL Databases, why would they need a DBA to manage the databases, isn’t the managed service managing them for you? Well, it’s simple, your needs might not be completely aligned with the service level agreements that are offered. Take a second and read Amazon RDS SLA and then Azure SQL Database SLA. Keep in mind, I am not telling you to not leverage these services; I just want you to know what is covered and what gaps DBAs can still fill. If you also take a look at Amazon RDS Best Practices you see several things that can keep DBAs busy.
Did you notice any mentions of your data in the SLA’s?
Is anything mentioned in writing about what will happen when stack dumps occur or data corruption happens? Did you see anything written on how you get notified if corruption happens and what actions will be taken on your behalf that might cause data loss, or if you should make business decisions and take action?
Thinking this could not happen to you? I ask because while performing our health check on a non-Microsoft cloud PaaS provider for a new client, we detected stack dumps… and this was the first time our client was notified, yikes!
The DBA Profession Is Not Going Away
To wrap this up, I don’t see the DBA profession going away. The DBA role has pivoted and evolved constantly over the years. I don’t see that changing. It’s one of the many reasons why I am passionate about helping clients solve their business problems with SQL Server. While some think machines are close to automating away your job as a DBA, I would hate it if new DBAs or experienced DBAs see written content like this and assume they need to change their career. Not only do I respectfully disagree, I do not see this happening and I am not alone.
When you want to focus on growing your skills, I see several benefits towards investing time both inside and outside of the role of a DBA.
I think automation will enhance good DBAs and reduce time spent on repeatable trivial tasks allowing DBAs to move faster and provide more value. I don’t see good DBAs being replaced by a handful of PowerShell scripts. To me, this is the DBA version of the sync button that allows turntablists to spend less time on preparing a mix and more time to providing a better experience to the dance floor.
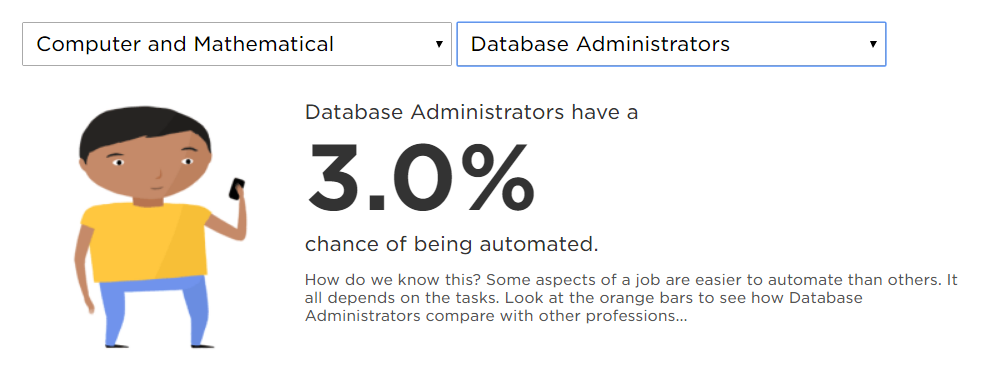
Seriously, don’t just take my words for it. NPR predicts only a 3% chance of automation taking over DBAs’ jobs. Even better, take a look at US Bureau of Labor Statistics you will see DBAs are not losing their jobs. When the tedious parts of both database administration and DJing have been automated away, it leaves people like me more time doing what we love. Embrace automation and find ways to add value so the business loves you.
Don’t make DBA stand for Don’t Bother Asking or you might get replaced by another DBA or a managed service provider.